🎉 最惊喜的产品
- Google NotebookLM,是一款Google推出的基于Gemini的笔记本,可以自定义上传文件、配合在线Deep research、网页和YouTube视频等作为资源,利用AI能力输出博客、演示文稿、闪卡(Anki er 福音!)、思维导图等。适用于论文阅读、网页总结等场景,令人震惊的AI能力之精美和Google整合的资源。
- **Apple Fitness+**,在Apple one中的提供运动建议的一款软件,其功能包括选择不同类型的运动(冥想、瑜伽、Hit等),同时可以配合Apple watch提供实时监测,并将数据传递到健康中,除此之外并无广告并其他打扰。相比国内的华为健康、Keep软件塞满广告的营销手段,Apple凭借其垄断的地位给出最优雅简洁的解法。
- Kindle oasis3 - 香槟金 - 2019款,之前使用的电纸书是掌阅的smart xs pro - 2021 - 7.8inch,但是总感觉文字渲染有点糊,由于KPW握持手感不佳,因此选择了oasis的最后一代。到手后发现虽然其反应速度、显示屏硬件参数落后,但是其做工极其精致、字体渲染超过掌阅半级,非常值得收藏。可惜的是只能通过网页使用微信读书,非常耗电。


💻 好用的软件
- Google NotebookLM、Apple Fitness+ 见上
- Apple Notes,兜兜转转 Flomo、Logseq、obsidian、feishu、Notion、Craft等等,最终还是回到最原始的记录方式来管理自己的所思所想,今年达成了「52周全部写完了周记」的成就,希望明年仍然可以坚持。
- Raycast,由于有 Mega support,一直舍不得放弃Alfred,但是由于受不了其简陋的界面和复杂的操作逻辑,转向了免费的 Raycast ,其AI功能、插件非常完善,同时订阅了Pro功能来支持跨设备同步,让我意识到每个人的配置是这款软件对自己最大的价值。


🧰 好用的硬件
- Kindle oasis3 - 香槟金 - 32G - 2019,见上
- AirPods Pro3,在摩尔定律逐渐失效的现在,已经很少有硬件可以实现功能上的代际提升,在从Pro2转换到Pro3中,可以毫不夸张的说降噪能力提升了两倍,完全遮盖了旁边拆迁的声音。
- Macbook Pro M1 - 2020,这完全是反性能的例子,在有MBP和14600K作为主机,自己的 Mac 性能不再是首要选择参数,淘了一台2020的楔形设计的M1的MBP,包含有Touch bar,堪称是艺术品的巅峰。

🎮 好玩的游戏
- 蕉力全开 - NS2,Donkey King用自己的拳头可以咋开一切碎石,真的是太爽了,没有复杂的技能树,看到阻碍砸掉就行了。
- 潜水员戴夫 - Steam,非常解压的游戏,海底的探索就想自己的欲望,常常在往获取更多资源 –> 潜水更深处 –> 氧气耗尽 – > 潜水技巧提升 –> 探望更深处 的循环中追求捕猎的快乐,同时害怕氧气耗尽的惩罚。
- 王国之泪 NS2版本,优秀的机能才能配得上这款游戏,相比switch1版本的画面质量和加载速度真的是好太多,唯一的缺点是其中有很多令人恶心的大花,有点恐怖。
- 金铲铲 - 巨龙之巢 - IOS,优秀的机制,同时也是三年前赛季的回忆。

📺 好看的剧集
- 人生切割术 - Apple TV,脑洞非常大的一部剧,以生活和工作分离,讲述了「工作的自己」和「生活的自己」如何突破自己的记忆,直到接受并完成自己奴役自己的过程,初识不知曲中意,再识已是曲中人。
- 同乐者 - Apple TV,仍然脑洞非常大的一部剧,“病毒”(或者是社交媒体、或者新时代的共识)让每个人变得意识连接在一起、期望所有的人都变得“快乐”,那么正确便无从谈起,不禁让人反思复杂的信息流、推荐系统、互联网所构建的连接关系是否将自我的生活附依在集体的定义之下,无法评价那种方式是更好的,但是希望每个人可以拥有选择和退出的权利。
- 老友记 - B站,永远可以提供开心的一部剧。

📖 好看的书
- 《被讨厌的勇气》,成长的过程便是自己和自己的对抗的克服。
- 《平面国》,抽象但是深刻,幸好暂时没有遇到。
- 《微小的总和》,远离消费主义。
🎵 好听的歌曲
- 《孙燕姿 - 开始懂了》,歌词真的太棒了,从喜欢《我怀念的》算起已经是8年孙燕姿的粉丝,虽然前6年都以为是林俊杰的歌。
- 《陶喆 - 就是爱你》,永远爱R&B!
- 《汪苏泷 - 晴》,这该死的宿命感。
📍好玩的地方
- 广州 - 顺德 - 蒸四味,非常地道的蒸鲮鱼,完整的鱼上桌太棒了。
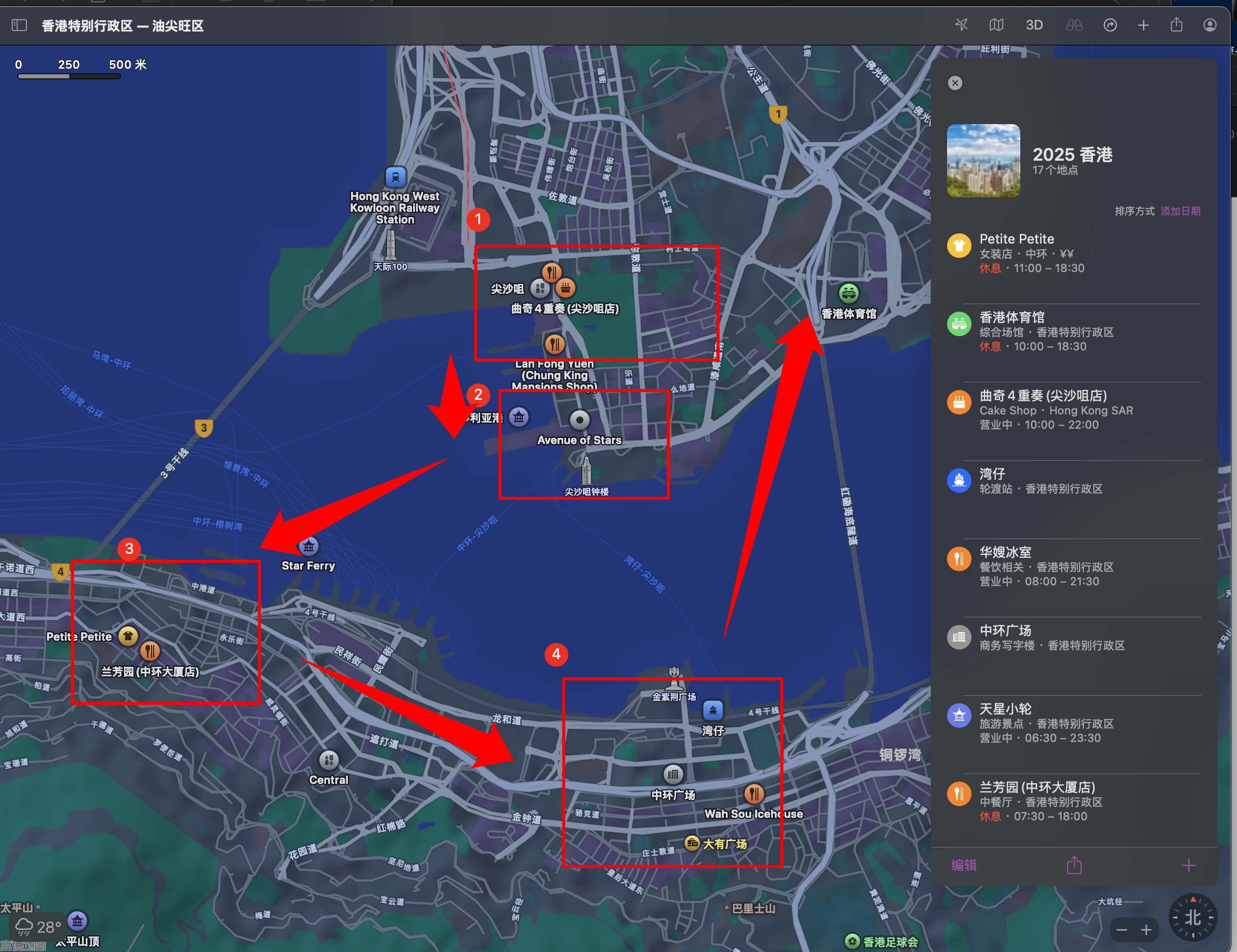
- 香港 - 天星小轮 - 港口,因为今年在广州的缘故,就近去了五次香港,最喜欢的还是坐在港口前吹着风,看着清澈的海水,空闲的时间总是很快的溜走了。
- 三亚 - 沙滩,躺平在沙滩上可以治愈一切。
- 广西 - 桂林 - 桂海晴岚,大草坪+ 喀斯特地貌有一瞬间觉得进入的旷野之息之中,原来我喜欢的并不只是游戏,而是自由呼吸的自由。

⏰ 最难忘的时刻
- 2025年1月TRB会议,第一次参加学术会议感受了纽约的烟草味,也感受到自己历年摸索的共鸣,知道在世界上的另一个遥远角落里也有一批人在研究相同的问题,产生了莫名的连接。
- 2025年5月研究生毕业,从大四进组开始,经历了“磨砺”人的 xx 项目直到完成毕业论文,没想到自己的学生生涯会结束的如此急促,远程的完成了所有的准备工作,匆匆忙忙的完成中期答辩、初稿、终稿、PPT制作,在唯唯诺诺中完成了答辩,终于毕业了!
- 2025年6月征服峨眉山,作为毕业旅行的最后一场,用了9个小时爬升17.35公里穿过了阎王坡、钻天坡,突破了自己的极限,永远忘不了一起走过的傻狗,也完整的和自己的学生生涯做了最后的告别。

2026年就这么来了,期待生活和工作中会有新的惊喜发生,希望今年会有月球移民,毕竟现在是曾经是小时候故事中的未来。
]]>🎉 最惊喜的产品
- Google NotebookLM,是一款Google推出的基于Gemini的笔记本,可以自定义上]]>




































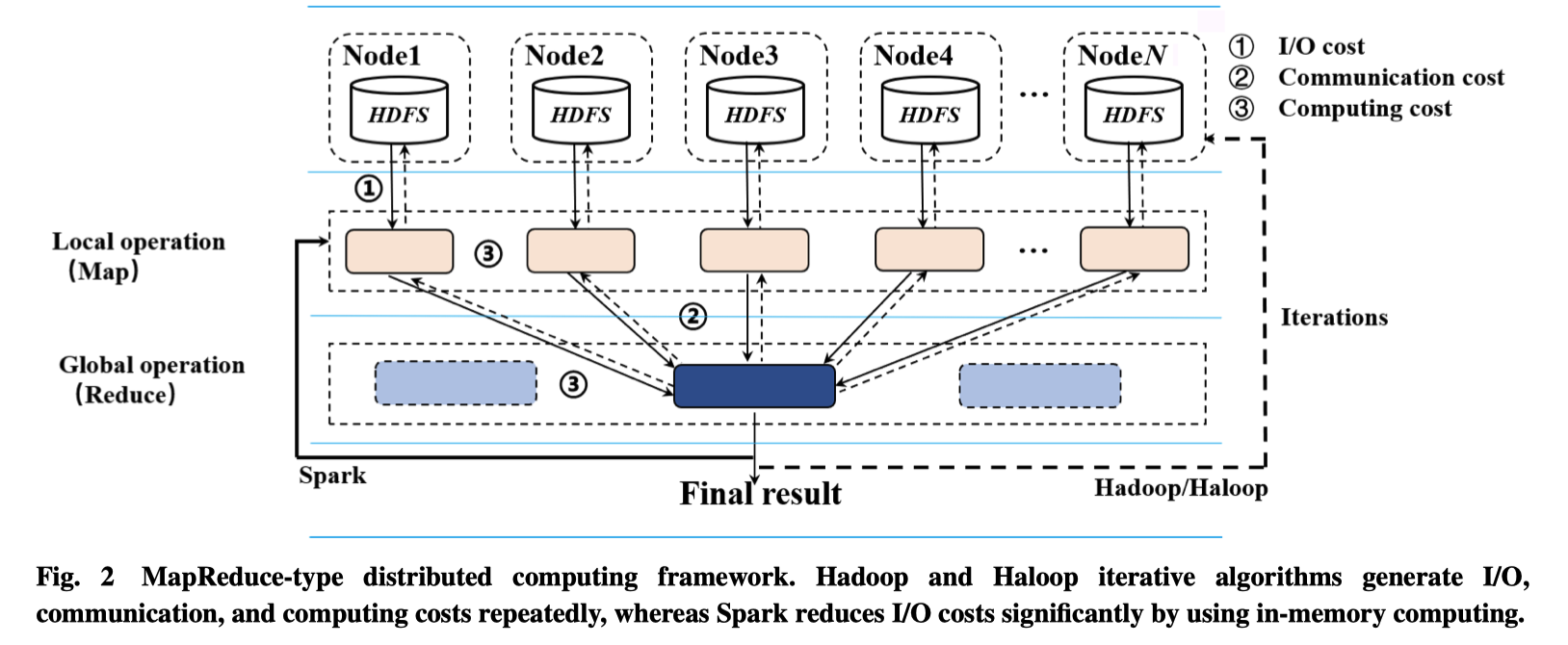







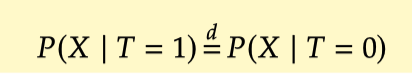 ,通过保证 X 和 T之间相互独立的状态,可以实现两者满足可交换的假设,进而准确的计算因果效应。如何实现协变量均衡可以从:
,通过保证 X 和 T之间相互独立的状态,可以实现两者满足可交换的假设,进而准确的计算因果效应。如何实现协变量均衡可以从:






























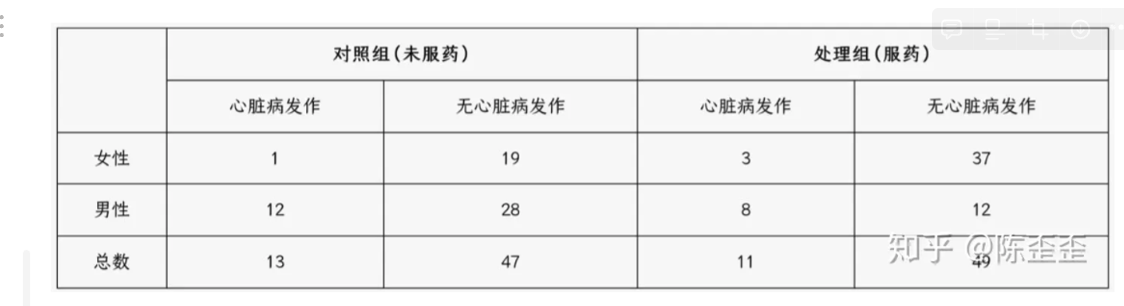
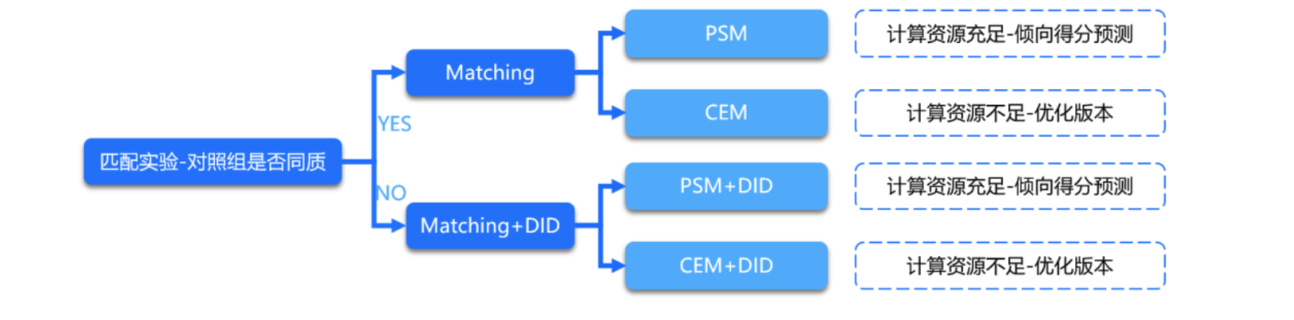
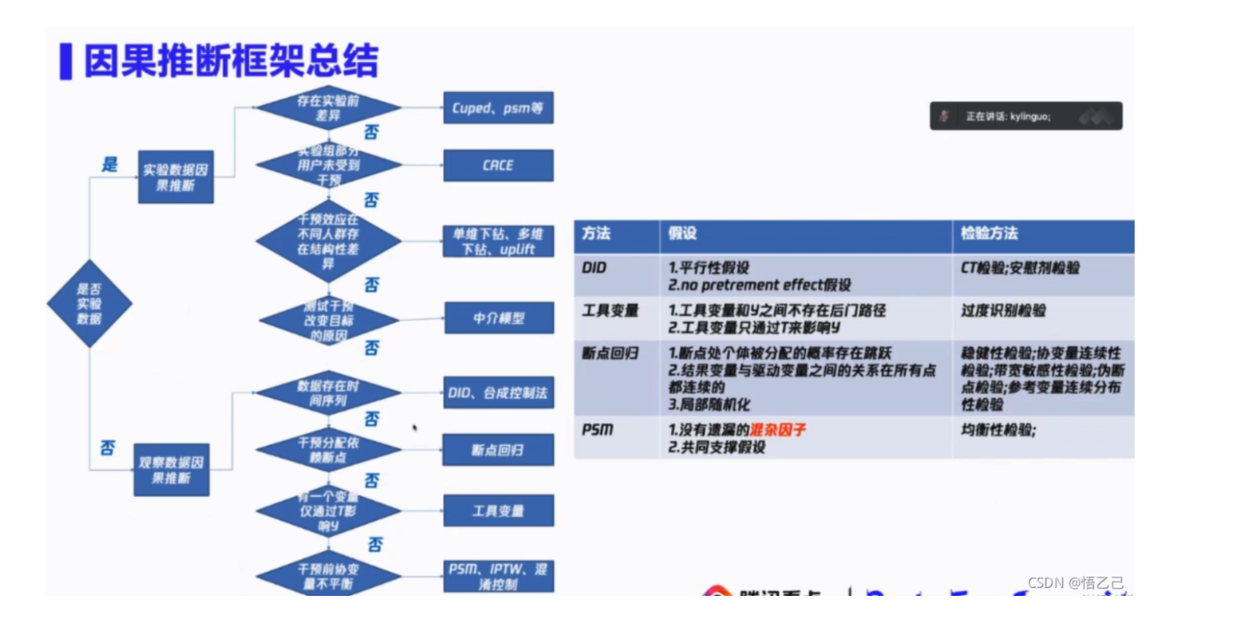
 个人总结
个人总结