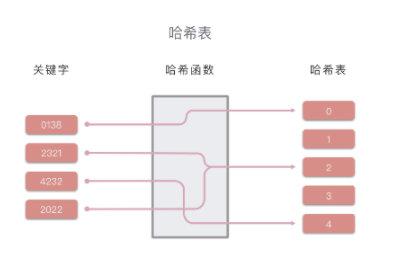
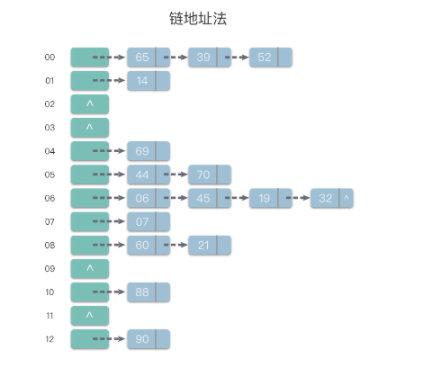
def__init__(self): self.set=[[] for _ inrange(1000)]
defadd(self, key: int) -> None: index=key%1000 for i inrange(len(self.set[index])): ifself.set[index][i]==key: break self.set[index].append(key) returnself.set
defremove(self, key: int) -> None: index = key%1000 for i inrange(len(self.set[index])): ifself.set[index][i]==key: self.set[index][i]=-1 returnself.set
defcontains(self, key: int) -> bool: index=key%1000 for i inrange(len(self.set[index])): ifself.set[index][i]==key: returnTrue returnFalse
classSolution: deftwoSum(self, nums: List[int], target: int) -> List[int]: headMap={} for i inrange(len(nums)): if nums[i] in headMap: return [i,headMap[nums[i]]] headMap[target-nums[i]]=i
class Solution: deffourSumCount(self,nums1:List[int],nums2:List[int],nums3:List[int],nums4:List[int])->int: hashMap1={} for num1 in nums1: for num2 in nums2: ifnum1+num2in hashMap1: hashMap1[num1+num2]+=1 else: hashMap1[num1+num2]=1
count=0
for num3 in nums3: for num4 in nums4: if-(num3+num4)in hashMap1: count+=hashMap1[-(num3+num4)]
class Solution: def maxPoints(self, points: List[List[int]]) -> int: n = len(points) if n < 3: return n ans = 0 for i in range(n): line_dict = dict() line_dict[0] = 0 same = 1 for j in range(i+1, n): dx = points[j][0] - points[i][0] dy = points[j][1] - points[i][1] if dx == 0 and dy == 0: same += 1 continue gcd_dx_dy = math.gcd(abs(dx), abs(dy)) if (dx > 0 and dy > 0) or (dx < 0 and dy < 0): dx = abs(dx) // gcd_dx_dy dy = abs(dy) // gcd_dx_dy elif dx < 0 and dy > 0: dx = -dx // gcd_dx_dy dy = -dy // gcd_dx_dy elif dx > 0 and dy < 0: dx = dx // gcd_dx_dy dy = dy // gcd_dx_dy elif dx == 0 and dy != 0: dy = 1 elif dx != 0 and dy == 0: dx = 1 key = (dx, dy) if key in line_dict: line_dict[key] += 1 else: line_dict[key] = 1 ans = max(ans, same + max(line_dict.values())) return ans
class Solution: def subdomainVisits(self, cpdomains: List[str]) -> List[str]: ans={} for domain in cpdomains: count,domains=domain.split() count=int(count)
subdomains=domains.split('.') temp='' for subdomain in subdomains[::-1]: if temp: temp=subdomain+'.'+temp else: temp=subdomain if temp in ans: ans[temp]+=count else: ans[temp]=count res=[] for key,value in ans.items(): res.append(str(value)+' '+key) returnres