大数据与分布式系统概述
这里系统自顶向下的对于大数据系统下的分布式平台做一次综述,包括一些简单的实际操作。
一、背景:什么是分布式系统
A brief introduction to distributed systems
分布式系统是以单一完整系统(Single coherent system)为表现的自助计算单元的集合(Collections of autonomous computing elements),实现的技术基础为:
- Node 性能强大的微处理器
- 高速发展的计算机网络
为了完成上述目标,分布式系统需要满足一下四个准则:
- 资源共享,包括外围设备、存储设备、数据、文件、服务和网络
- 分配透明化
- 开放性
- 具备可拓展性
分布式系统的主要特点包括:
- 分布式(Distribution):节点可以分布在不同的计算机上
- 同步 (Synchronization):多个节点可以通过执行任务
- 异步(Asynchrony):节点之间通过信息传递进行通信,不同节点可以再不同的时间执行不同的任务
常见的分布式系统为:
- 高性能的分布式计算,包括集群计算、网格计算、云计算
- 分布式信息系统(不懂)
- 普适系统(不懂)
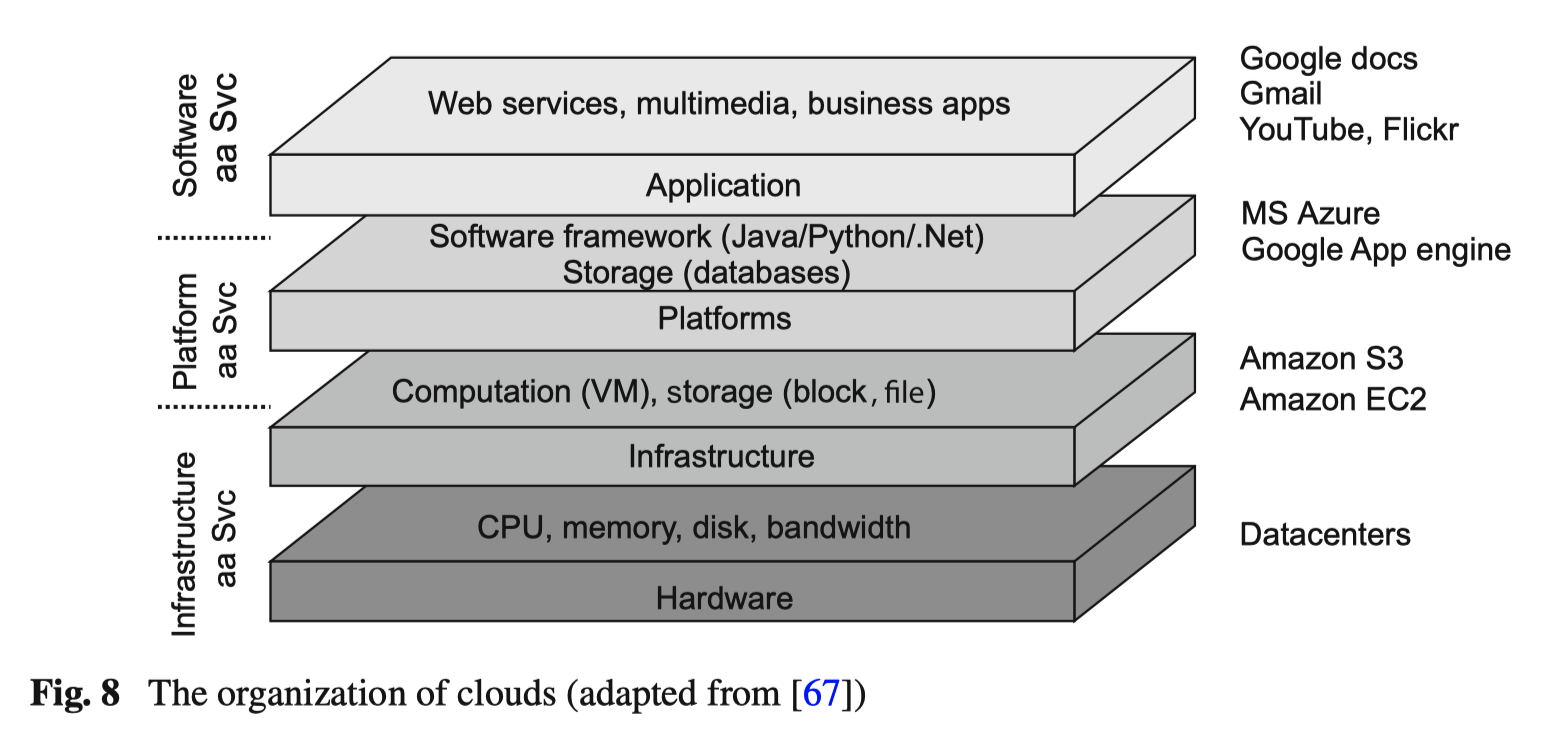
二、分布式计算框架组成
Survey of Distributed Computing Frameworks for Supporting Big Data Analysis
分布式系统架构 (System architectures)
分布式系统需要大量的硬件资源:硬盘、内存、CPU/GPU、传输带宽、IO 速度,这样的系统框架可以分为
- HPC,高性能计算系统常见的是用于解决复杂科学、工程和学术问题的超级计算机大型集群,特征是通过并行计算加速任务执行,通常处理的是高度复杂的计算机任务,包括气象模拟、基因组分析、流体动力学模拟
- Cluster computing,主要用于并行处理、分布式计算和大规模数据处理,集群的目的是通过协作提高系统的可拓展性和可靠性
分布式文件系统 (Distributed file system)
将一个大数据文件分区(partition)成为数个小文件块(data block)存储再分布式集群(cluster)中的节点(node)里,常见的分布式存储系统包括:
- GFS(Google File System)
- HDFS(Hadoop Distributed File System) from Apache Hadoop
- TFS(Taobao File System)
- FastDFS
- CEPH:统一分布式存储系统,支持对象、块和文件存储
分布式数据库
HBase,在上述文件系统的基础上,如基于 HDFS 构造NoSQL 的数据库 Hbase ,通过 HiveSQL 将 SQL 语句转换成为 Map Reduce 语句来实现计算功能。其本身并不是真正意义上的数据库,只是将结构化的数据文件转换成为一种数据库表,因此本质上是一种内存的 Hash 表,所以其相对于传统的关系型 SQL 会需要加上 Partition 和 Bucket 的字段
ClickHouse 用于联机分析处理的开源列式数据库
ElasticSearch 基于 Lucene 库的全文搜索引擎
Redis Cluster基于内存的键值对数据库
Mongo DB
Cassandra
DynamoDB
TiDB
注:普通的关系数据库的区别
普通的关系性数据库常见的使用的是服务器本地的文件系统,利用自身设计的计算模型来实现实时查询,具备介绍的拓展性
分布式计算处理框架 (distributed process)
分布式计算是通过将算法切分成可以并行的处理框架来实现高效的计算效果,其最基本的思想是通过“分治法(Divide-and-conquer)”来进行计算,通常可以分为是基于离线数据处理和在线数据处理两种方法,常见的处理框架为
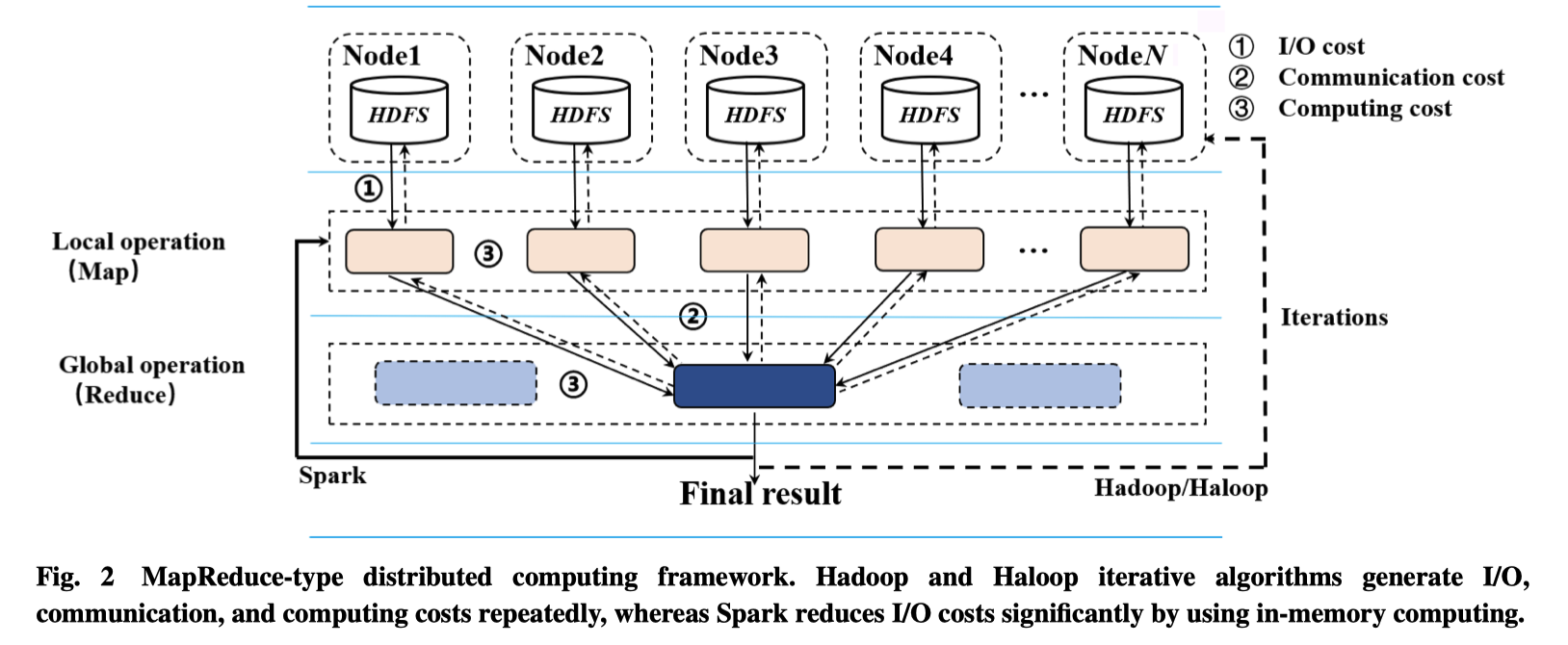
- Apache Hadoop,基于 Mapreduce 模型,主要用于处理大规模数据,Hive 是基于 HDFS 的数据仓库工具,用于数据提取、转化和加载、可以实现数据存储、查询和分析存储的大规模数据的机制,适合用海量数据做数据挖掘,但是实时性较差,但是计算能力和存储拓展方便
- Apache spark,基于内存的数据处理,是强大的分布式处理框架,处理速度更快,且更加适合迭代计算的任务,主要组件包括 Spark core、Spark streaming、MLlib、GraphX
- Apache Flink,流处理框架
- Kafka Streams,允许直接在消息中处理数据,用于消息传递系统中进行流式计算
- Map-Reduce ,最原始的版本,在单一节点上进行计算来得到本地结构 local result,汇合多个节点的计算结果,来得到 global result
其余的平台(platform)与包(package)
- 基本程序语言:JVM、Java、Scala(面向对象和函数式编程)、Python
- 采集和传输:Kafaka(分布式订阅消息系统)、Flume、Datax
- 数据湖:在数据存储和数据处理之间:Iceberg、Hudi
- 资源调度框架:YARN、KUbernets、Mesos
三、如何学习分布式计算系统
2.1 编程基础
Scala基础
Scala 是一门类 Java 的编程语言,结合了面向对象编程和函数式编程
- 每个值都是一个对象,对象的类型和行为由类定义,不同的类可以通过混入的方式混合在一起
- 函数式编程芋圆,原生支持嵌套函数定义和高阶函数
PySpark 基础
需要深刻理解如何使用 pyspark 来完成 spark 的算力的厂检查熬做
2.2 计算框架 Spark
关键的Topic 包括
- 快速理解 spark 的 API
- 理解如何使用 RDD 来进行编程、核心 API、加速和广播操作
- 理解 SPARK 的 SQL、Dataset、Dataframe,利用最新的操作 API
- 流处理structured streaming、spark streaming(可选)
- 机器学习库 MLlib
- 图网络学习 GraphX
- 利用 R 语言来进行学习(可选)
- 利用 Python 来使用 Spark
2.3 额外知识
SQL - CRUD
HDFS - 常见操作
Flink 流数据处理 pipeline(可选)
- 首先利用 Flink 从实时流数据采集中获取数据流,例如用户的行为日志
- 利用 Flink 处理的 api 来完成数据的清晰、格式化和特征提取操作(基于 MapReduce)
- 调用深度学习模型来完成预测,Map 操作
- 将更新的数据输入到 Kafka,或者根据应用常见写入到数据库、消息队列或者文件系统中
四、其他问题
流数据(Stream data)和批数据(Batch data)处理的区别?
- 流数据是连续生成,需要实时采集并实时处理,通常的数据来源包括传感器用户日期和、社交媒体更新、金融交易等操作。
- 金融服务的交易分析,比如检查用户的行为
- 实时用户和推荐系统,比如实时分析用户的需求
- 批数据模式下,数据是成块或者成批次组成的,通常被定时的收集或者存储
- 金融网贷业务的预处理
全量更新和增量更新
- 全量更新 (Full update) 每次更新的时候处理整个数据集
- Pro 实现逻辑简单,不需要复杂的变更追踪的逻辑,每次更新都是完整的数据集,可以直接避免数据不一致的风险
- Con 每次都需要处理全部数据,对于系统资源要求高。特别是对于大型数据集需要很长时间才能完成更新
- 增量更新(incremental update)只处理上次更新依赖发生变化的数据
- Pro 增量更新的效率高、实时性更强
- Con 但是面临数据处理逻辑的复杂性,容易造成数据不一致的风险,对历史数据管理要求较高
增量更新常见的操作是根据 key 和 update time 来保留最新的记录
对应的表格分类包括:
- 增量表:记录更新周期内新增的数据,在原表中数据的基础上新增本周起产生的新数据
- 全量表:记录更新周期内的全量数据,无论数据是否有变化都需要记录
- 拉链表:记录数据的历史信息,记录数据从开始 i 一直到当前所有变化的信息