原文地址:A Review of Off-Policy Evaluation in Reinforcement Learning
个人理解的背景介绍
强化学习(reinforcement learning)在许多的领域中用于支撑得到行为决策过程。其简单的过程可以根据是否存在完整的可交互的环境划分为两类学习的策略 online learning 和 off line learning
- 在线学习的过程就是可以做单步的状态更新并不断的收集信息,可以根据收集的信息来做出智能体策略的提升,同时可以将提升之后的智能体立即的应用于环境之中来根据奖励判断优劣。这个过程中更加重要的是 1. 如何收集可靠有效的信息来帮助智能体提升有自己、2. 利用什么样的算法来提升智能体的策略
- 离线学习的过程就是只能收集到历史的观察数据,在这个基础上根据历史的数据来提升智能体的策略、评估不同策略的优劣。在这个过程中的难点在于无法从环境中得到现有策略下的真实的输出是什么?以及在数据集状态和更新策略之间存在反事实的过程
0x01 引言
RL 的主要任务是从在序列决策问题中确定最优的策略来最大化时序奖励。同时在近些年中RL 在游戏、推荐系统、共享出行、自动驾驶等领域具有广泛的应用。
在本文中侧重于 off-policy evaluation(OPE),主要研究的问题在于如何评估一个策略的优劣(or 输出的奖励值),可以看出在 online 或者 off line 中都存在这个问题,但是对于在线学习过程中,我们可以使用不同的策略来进行探索来收集无偏的数据;对于 off line 学习中,我们无法手机不同的策略,因此只能通过存在历史偏差的数据来进行策略效用的评估
? 个人理解的例子
如果 社会=环境、公司不同算法模块 =智能体、业务收益=奖励;如果我们可以尝试所有的算法模块,也就是针对整个环境采用 AB 实验的方法,利用这样的方式得到的数据是无偏的并且是可以有效提升算法(智能体)结果,在之后的探索中可以使用更新的策略来继续收集不同动作下的奖励;但是对于不能做 AB 实验场景下的结果,比如 B 端司机的优惠卷方法,这个过程是无法得到不同策略下的准确输出的,这个只能采用历史有偏的数据来获取可能的状态转移过程
除此之外,在一些昂贵、危险和不道德的场景中,无法根据实验,这个时候需要确定训练策略的不确定性。
因此 OPE 可以看作是一种统计估计和推断问题(Statistical estimation and inference problem)问题;在统计文献中,OPE 可以看作是在历史数据和决策问题的情况下如何判断病人潜在的凡事死输出的模型。统一来说,确定性决策策略(Dynamic treatment regimes,动态治疗策略方案,DTR)或者说是治疗方案可以看作是一种根据病人的信息来给出对应的质量方法,在这个过程中 OPE 希望用于估计出每个治疗策略(对于所有用户)下在历史数据的基础上评估的优劣程度(可能并不需要学习出完整的奖励函数)
OPE和 IRL 之间的区别和联系
OPE 是根据历史数据来判断不同策略的优劣,采用的是根据历史采用的 SARS 的方式来计算对应的结果,唯一的限制是采集到的数据可能是存在选择偏差的
IRL 是根据智能体的行为来生成对应环境中的奖励函数的,这里采用的是基于模拟专家的方式来学习环境中适合的智能策略
我们可以发现在现有的统计领域中通常有使用潜在输出框架(potential outcome framework)来描述可能的利益估计(Estimation of the interest),并增加无混淆变量和策略一致性的假设(详细见因果推断相关基本假设过程);但是在 RL 领域,通常采用MDP 过程假设的方式,利用最大化多步奖励的方式来衡量潜在策略的优劣,为两个领域之间相关隔离但是研究的相似的问题,本文尝试给出统计角度的 ope 的相关基本概念,来描述常用的方法和解决的问题,帮助人们更清楚的理解背后的过程。
最近出现很多有关统计学习方法来OPE,但是这些方法往往适用于离散甚至二元的方法策略,但是在实际过程中往往是无限的策略,这种尝尝在很多领域都有所设计,尤其是自动驾驶、机器人和共享交通领域。例如 IPW 估计运用于少量离散场景下很难直接拓展到多离散动作下的场景:
- 首先,这些逐步方法与有限多个轨迹不一致
- 其次,众所周知,这些逐步方法会受到探索边界的诅咒,即其均方误差(MSE)相对于地平线增长快没,例如对于Non-MDP(NMDP)
同样最近在计算机科学中相关的研究表明:如果通过增加一些往外的结构,例如增加马尔科夫性质和时间均匀性质,可以缓解这些条件
- 在 MDP 过程中可以有效的降低上述的 MSE 的损失
- 时间均匀性允许我们可以从一个单一的轨迹中构建高效的估计器
这些是之前在统计领域相关所没有考虑到的
总的来说这篇文章回顾了 OPE 问题,从一个统计的视角来尝试融合计算机科学中的相关就方法来弥补长步骤 or 无限步骤下的状态估计问题。1. 首先回顾了最佳渐进 MSE 估计(也成为效率边界 efficiency bound)2. 之后讨论相关 OPE 方法在计算机科学,并总结他们对应的优势和局限性
Section2:介绍多臂老虎机下的 OPE 问题
Section3:在 NMDP 到时变 MDP 下的 OPE
Section4:时间均匀 MDP 下的 OPE,介绍每种情况下的效率边界的估计,并构建两个关键的 QW 函数
Section5:介绍重要的统计边界理论
0x02 从多臂老虎机说起
可以被认为是探索步长为 1 的 MDP 过程,也就是 non-dynamic setting,在这个问题中,OPE 的目标在于估计给定一个$\Pi^e$需要计算期望价值,对于一个给定的输入状态,我们可以使用 policy 来得到对应的动作的概率分布$A - \Pi^e(a|s)$,在因果推断领域,这里的动作分布往往是与状态无关的,他们真是估计估计平均效用的提升(ATE),如果动作空间是离散的,此时我们可以使用期望来表示,在这个过程中往往需要引入因果推断中常用的基本假设,此处略(感觉这个文章也没有说明白)
之后可以使用一些常见的估计器来计算对应的期望:
- 重要性采样的方法(importance sampling),或者 IPW 或者是 Horvitz-Thompson 估计。注意由于两个策略之间的差值可能非常大,这里采用归一化的方式来得到 self-normalized IS 方法
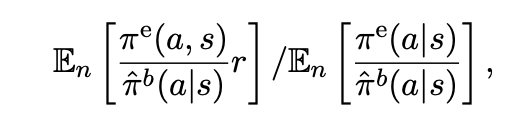
直接方法的估计(Direct method estimator),或者被定义为一种回归形式 regressing-type method,但是注意这个模型本身是存在偏差的
通过将 IS 和 DM 结合的方式,得到一种双重稳健估计,这篇文章给出的和之前看到的并不是完全一致:
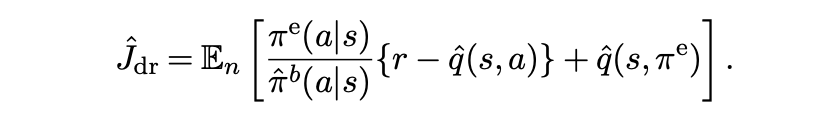
后面功力不够,看不下去了。。。。(希望有大神可以填坑讨论)