官方文档 pandas 的阅读和感悟
官方文档是开发者对自己代码的解释。对于成熟的框架,官方文档可以最准确、权威的资料。如何阅读英文的官方文档一直是作为Coder weaker和English weaker的心魔,这里以Pandas文档为例子,尝试给出自己对于阅读官方文档、官方文档的查询工具、代码注释和Pandas文档的总结。
0x01 Why 阅读官方文档
对于质量比较高的项目,其官方文档往往能反映开发者的最直接的思想,而互联网上经过许多人的编码和解码,导致最后的意思可能和本意相差巨大。虽然可能存在其他更好的教程,但是官方文档给出的思想一定是最准确、权威的。
之前一直不知道GitHub在国内为什么访问这么慢。 在网上找到很多答案,比如修改DNS的、修改Hosts的、修改镜像源或者增加代理的,但其实本质的问题是GitHub.com的域名解析在国内往往需要多层中转进而因为污染等原因造成速度较慢,因此上述方法对应的是修改DNS、本机解析、设置镜像、走代理等多种方法,这些方法都没有错。但是只是给出这些方法会让人不能一览背后的思想而困惑。
0x02 What 官方文档
以Pandas为例子,文档通常可以分为
- Getting start:新手教程,一般会教你如何搭建一个简单的应用示例。
- User guide:使用教程,介绍技术的关键知识、思想和概念。
- API reference:API文档,包括具体的API使用细节以及机制
- Developer guide:开发文档
image-20230507140000120
推荐使用 Dash gives your Mac instant offline access to 200+ API documentation sets. 来进行官方API文档的管理。作为一个API文档浏览器(API documentation brower)和代码片段管理(Code snippet manager),可以提供的帮助有
- 迅速
- 直接
- 本地
- Alfred协作
当然常见的函数用法可以直接通过命令来获取
1 | |
0x03 Pandas 新手教程
首先介绍pandas是什么:
Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python.
其中基本的数据类型可以分为Series和DataFrame两种,基于NumPy构建。新手教程给出常见的Pandas使用的Topic。包括
3.1 创建数据、查看数据、索引数据
1 | |
3.2 数据缺失处理、运算函数
1 | |
3.3 集合之间的处理:合并、分组、重塑和多索引
1 | |
3.4时间序列处理函数专题
1 | |
0x04 Pandas 用户教程
在用户教程中,Pandas提供了一些更加细致的专题。这里只给出有趣的话题
4.1 数据结构简介 intro to data structure
和第三章的类似
4.2 关键基础函数 essential basic functionality
Attention02:对于dataframe的操作可以三个维度:元素的维度、行或者列的维度、整个DataFrame的维度
1 | |
4.5 索引和选择数据 Indexing and selecting data
和新手教程差不多
4.6 多重下标和高级索引 MultiIndex and advanced indexing
和新手教程差不多
4.6.5 Merge、join、concatenate、compare
和SQL教程差不多
4.7 重塑和数据透视表
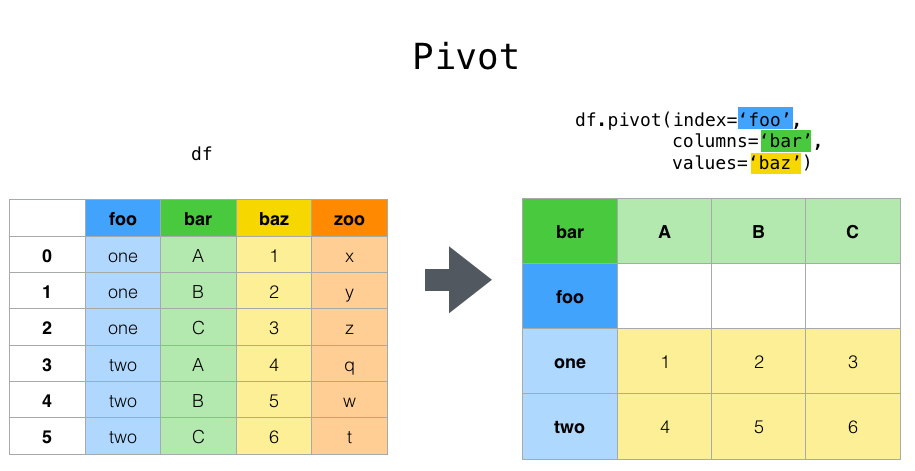
../_images/reshaping_pivot.png
1 | |
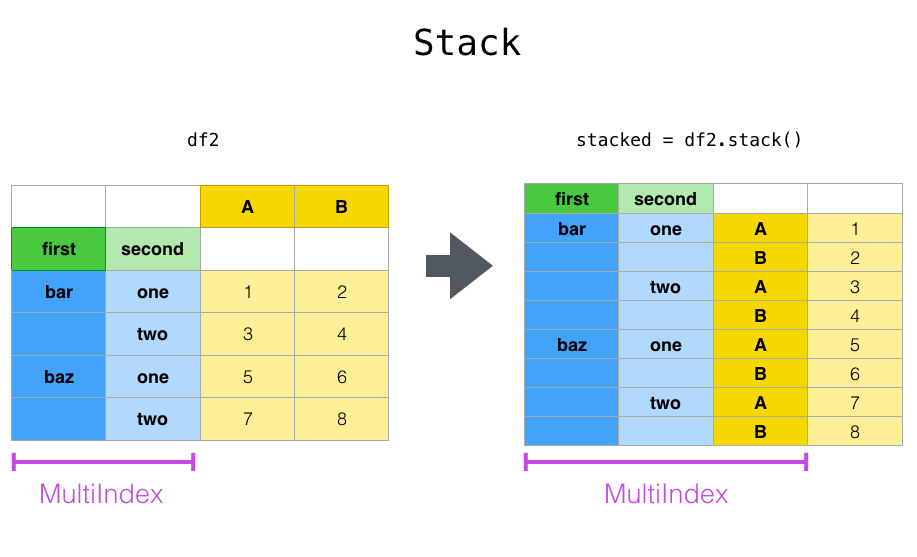
../_images/reshaping_stack.png
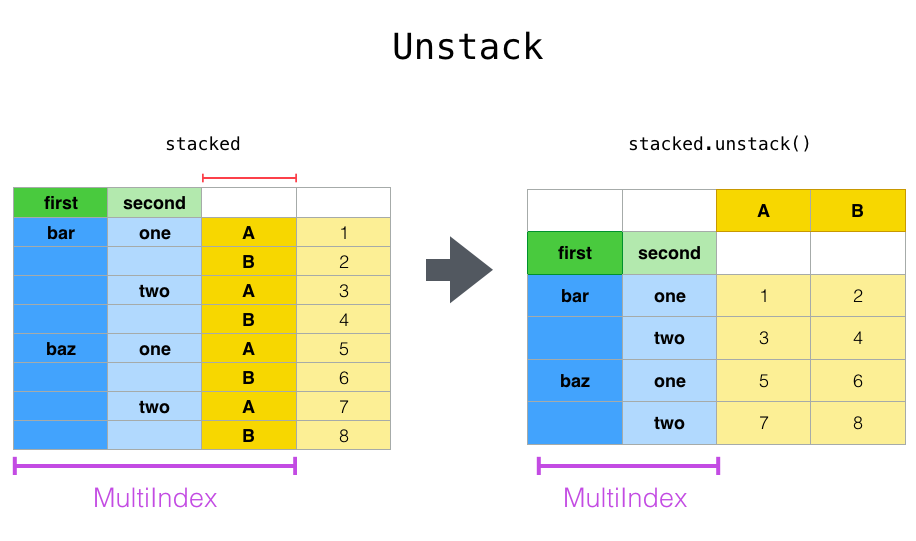
../_images/reshaping_unstack.png
剩余的太理论了~
0x05 心得
文档很多,但是其中给出开发者的default的选项,可以提高对其的理解。