Gym is an open source Python library for developing and comparing reinforcement learning algorithms by providing a standard API to communicate between learning algorithms and environments, as well as a standard set of environments compliant with that API. Since its release, Gym’s API has become the field standard for doing this. Gym是一个开源的Python库,通过提供标准API在学习算法和环境之间进行通信,以及一组符合该API的标准环境,来开发和比较强化学习算法。自发布以来,Gym的API已成为这样做的现场标准。
Gymnasium is a maintained fork of OpenAI’s Gym library. The Gymnasium interface is simple, pythonic, and capable of representing general RL problems, and has a compatibility wrapper for old Gym environments Gymasium是OpenAI gym library的一个维护分支。Gymnasium界面简单,pythonic,能够表示一般的RL问题,并具有旧gym环境的兼容性warp器
def__init__(self, arg1, arg2, ...): super().__init__() # Define action and observation space # They must be gym.spaces objects # Example when using discrete actions: self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS) # Example for using image as input (channel-first; channel-last also works): self.observation_space = spaces.Box(low=0, high=255, shape=(N_CHANNELS, HEIGHT, WIDTH), dtype=np.uint8)
defstep(self, action): ... return observation, reward, terminated, truncated, info
defreset(self, seed=None, options=None): ... return observation, info
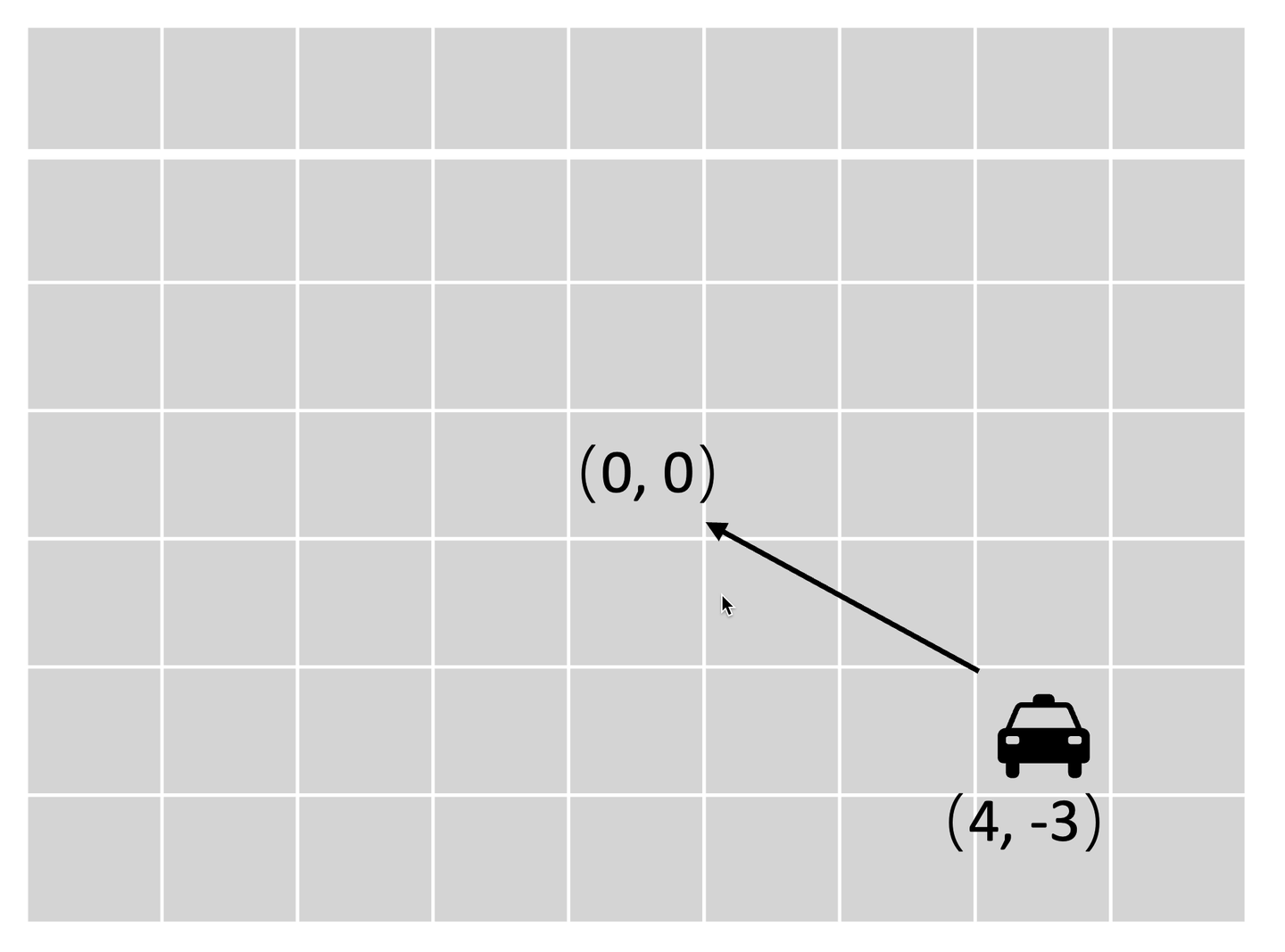
import gymnasium from gymnasium import spaces import numpy as np # Path: modelTimetable/DRL/myEnv.ipynb # Implementing the environment # Reproduction of the cartpole environment # # Discription: # Create a car in a two-dimensional plane with a width of 20, and the coordinates of # the center point are the destination of the car to reach. # # State: # The state of the car is represented by the coordinates of the center point of the car.(x,y) # Action: # The action of the car is represented by the speed of the car.(vx,vy) # Reward: # The reward is the distance between the car and the destination. # Termination: # The car reaches the destination.(0,0) # truncation: # The car is out of the screen.
''' gymnasium is the main class that we will use to create our environment.
The gymnasium class has the following methods: __init__(): This method is used to initialize the environment. It takes the following parameters:
step(): This method is used to take an action and return the next state, reward, and whether the episode is over. Physical engine - input: action - output: observation, reward,terminated,truncated,info
reset(): This method is used to reset the environment to its initial state. - input: None - output: observation
render(): This method is used to render the environment: Image engine - input: mode(default='human','human','rgb_array','ansi','rgb_array_list) - output: None eg:gymnasium.make('CartPole-v0',render_mode='human')
close(): This method is used to close the environment. '''
defstep(self, action): assertself.action_space.contains(action), "%r (%s) invalid"%(action, type(action)) # update the state by the action x,y = self.state if action == 0: x += 0 y += 0 elif action == 1: x += 0 y += 1 elif action == 2: x += 0 y += -1 elif action == 3: x += -1 y += 0 elif action == 4: x += 1 y += 0 # the next state self.state = np.array([x,y]) self.state = self.state.astype(np.float32) reward = self._get_reward() terminated = self._get_terminated() terminated = bool(terminated) truncated = self._get_truncated() truncated = bool(truncated) info = {} returnself.state, reward, terminated,truncated, info
def_get_terminated(self): x,y = self.state return x==self.target_x and y==self.target_y
def_get_truncated(self): x,y = self.state return x<-self.size or x>self.size or y<-self.size or y>self.size
from stable_baselines3.common.env_checker import check_env env = MyCar() check_env(env, warn=True)
测试它的输出输出
1 2 3 4 5 6 7 8 9 10
env = MyCar() env.reset() state,reward,terminated,truncated,info = env.step(env.action_space.sample()) log = 0 while not terminated: env.render() state,reward,terminated,truncated,info = env.step(env.action_space.sample()) if truncated: env.reset() log += 1
output
0x05 开始训练
这里只是调用stable_baselines的最简单的DQN库,没有调整参数和网络结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from stable_baselines3 import DQN from stable_baselines3.common import logger # Train the agent by the stable_baselines3 import os models_dir = './models/DQN' logdir = './logs' ifnot os.path.exists(models_dir): os.makedirs(models_dir)