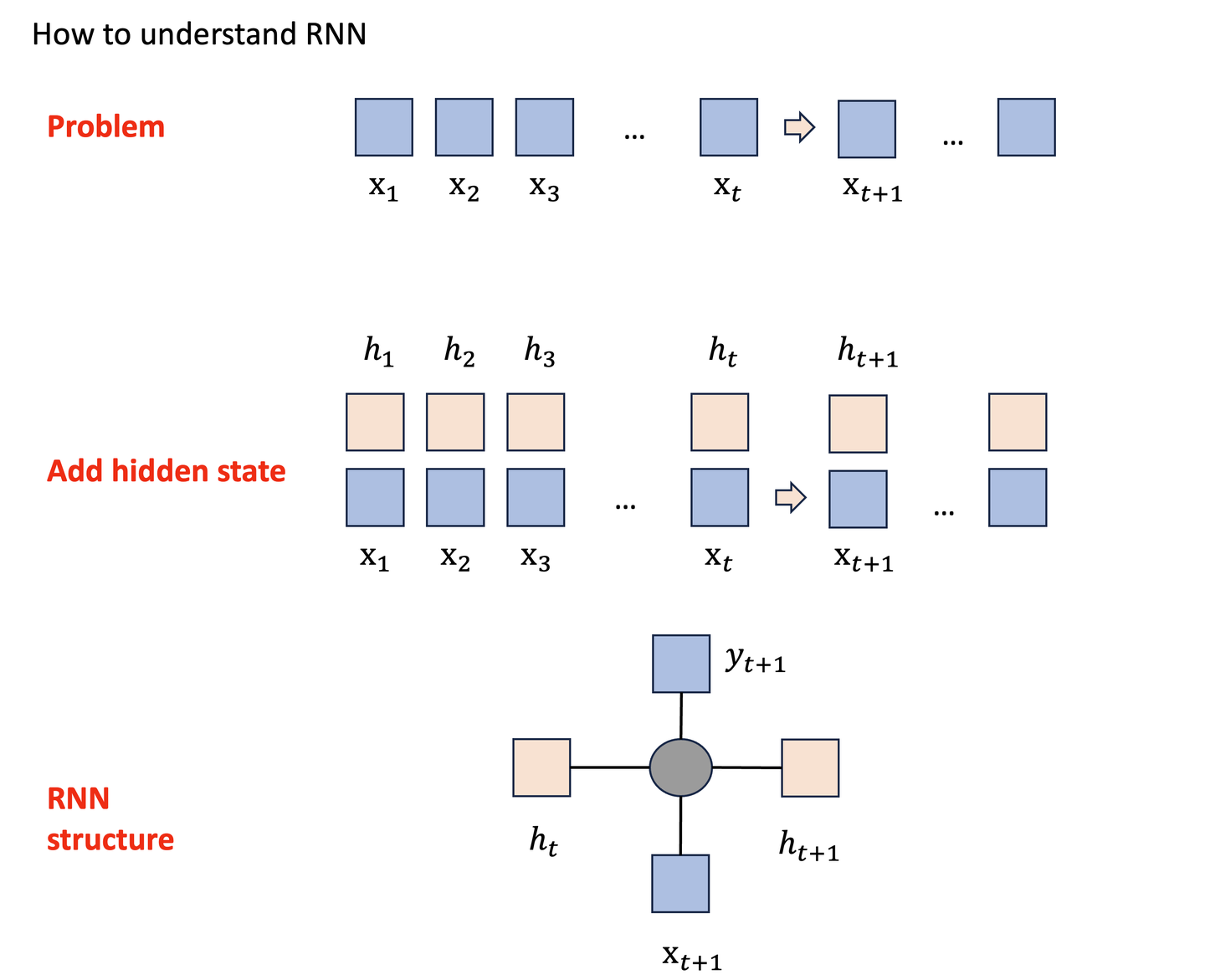
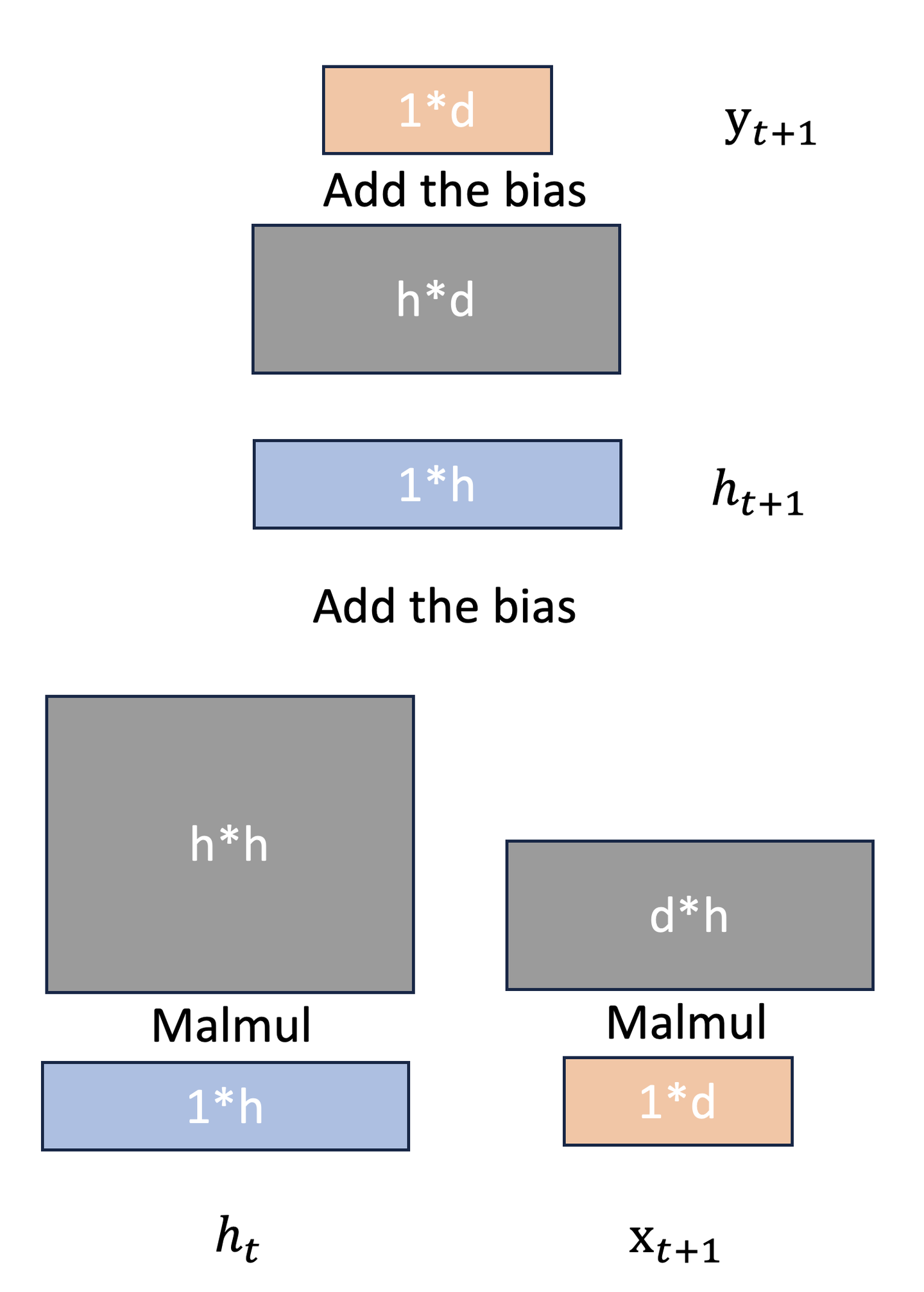
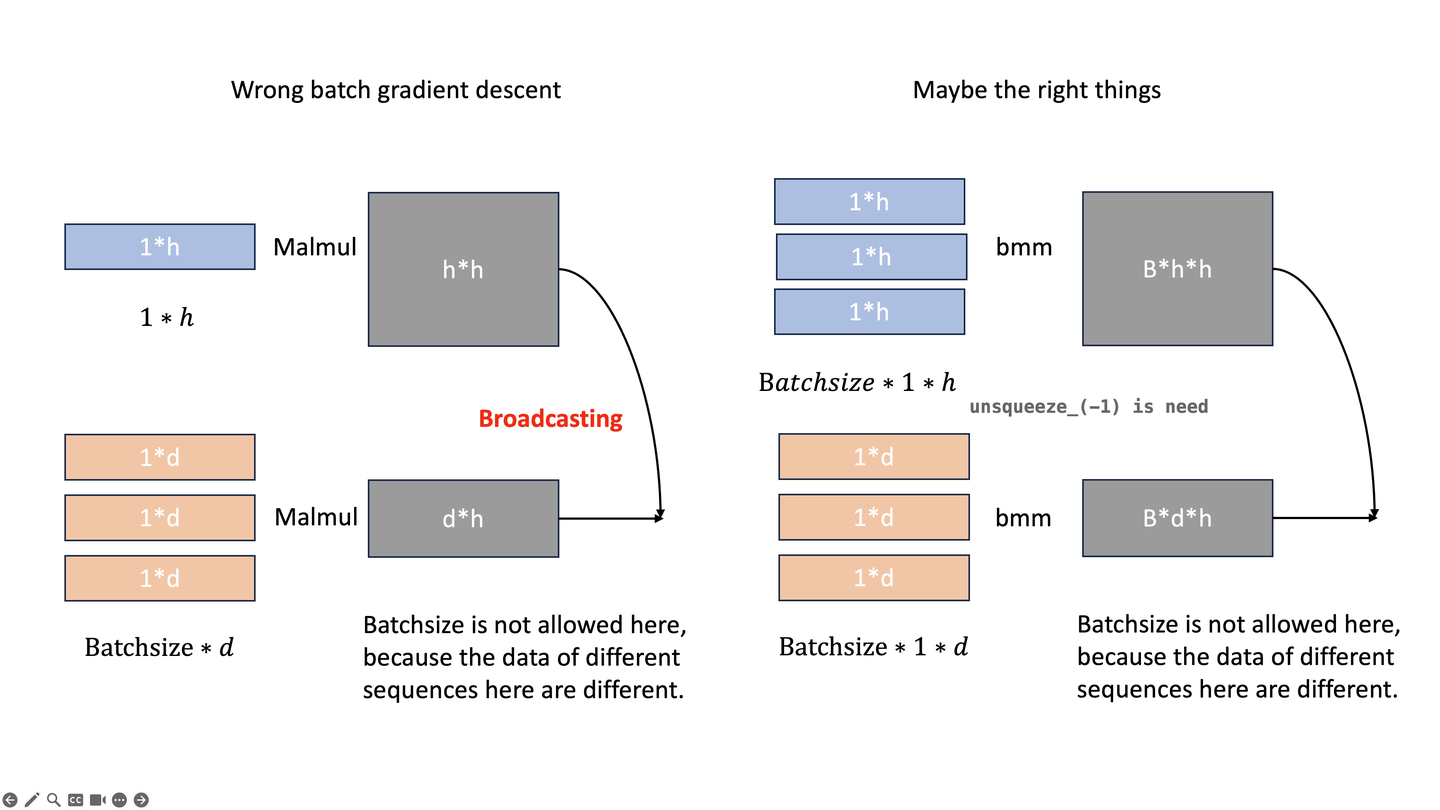
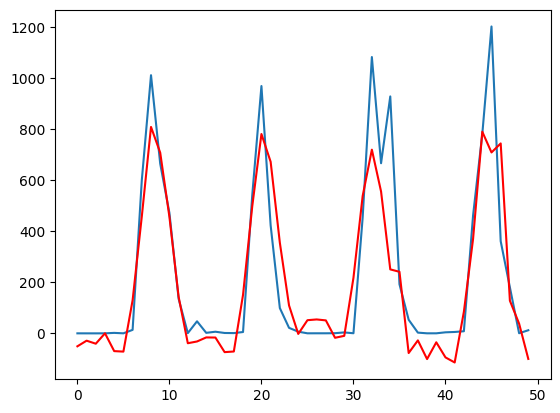
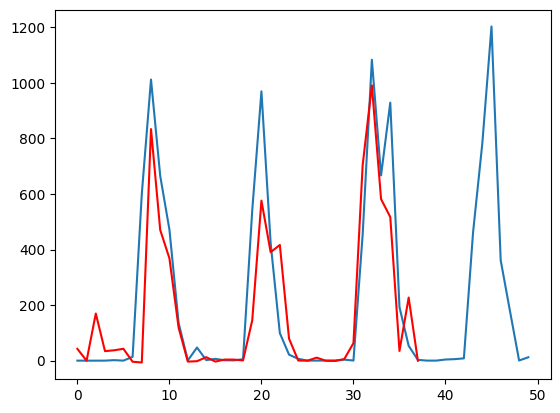
这里有点太晦涩了。当我们以时间序列预测(Time series forecasting)的方式来理解一个问题,我们如何从t的状态来预测t+1,经过分析我们会知道t+1状态并不完全取决于t。比如同一支股票在相同的价格均会存在下跌和上涨的状态,因此我们会希望另外一个隐藏值H来表示之前所有序列的状态,但是这个隐藏状态可能不能太长,导致隐含信息被平滑,也不能太短到无法提供信息。因此我们需要选择合适的WINDOW-SIZE。由此我们的估计值应该包括
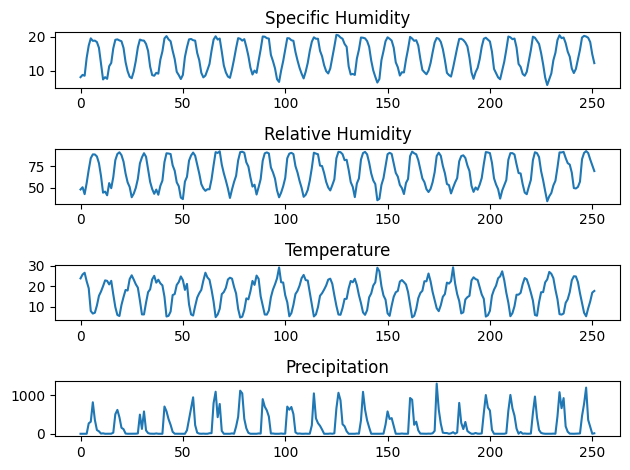
import torch import torch.nn as nn import pandas as pd import matplotlib.pyplot as plt import numpy as np df = pd.read_csv('../input/Rainfall_data.csv') df.info()
# Train the model and gets the params x = df['Precipitation'].values train, test = x[:len(x)-50], x[len(x)-50:] p = 12 model = AutoReg(train, lags = p) model_fit = model.fit() print('Coefficients: %s' % model_fit.params) params = model_fit.params
# Walk forward over time steps in test history = train[len(train)-p:] history = [history[i] for i in range(len(history))] predictions = list() for t in range(len(test)): length = len(history) lag = [history[i] for i in range(length-p,length)] yhat = params[0] for d in range(p): yhat += params[d+1] * lag[p-d-1] obs = test[t] predictions.append(yhat) history.append(obs) print('predicted=%f, expected=%f' % (yhat, obs))
print('The length of the dataset is:',len(train)) print('The length of the test set is:',len(test)) window_size = 12 definput_data(seq,ws): output = [] for i inrange(len(seq)-ws): output.append(seq[i:i+ws]) return np.array(output)
classMyRnn(nn.Module): def__init__(self, input_size,hidden_size,num_layers,output_size): ''' input_size: number of features hidden_size: number of hidden units num_layers: number of layers output_size: number of output ''' super().__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size)
defforward(self, x): h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) out, _ = self.rnn(x, h0) out = self.fc(out[:, -1, :]) return out
input_size = 4 model = MyRnn(input_size, hidden_size, num_layers, output_size).to(device) epochs = 5000 for epoch inrange(epochs): for x,y in train_loader: x = x.to(device) y = y.to(device) output = model(x) loss = criterion(output, y.unsqueeze(1)) optimizer.zero_grad() loss.backward() optimizer.step()