上一篇文章中介绍一个基本的机器学习模型线性回归实现的整个过程,将其步骤分为八个部分。之后D2L中介绍了soft Max、MLP等简单的模型。这里迈向深度学习,利用简单的卷积神经网络来介绍深度学习API的使用过程,从零开始搭建模型,将其分为数据集预处理、构建模型和训练及评估三个步骤。
0x01 Introduction of CNN 1.1 卷积的由来 我们可以将MNIST数据集中的输入变量(28,28)的二维张量给展平(flatten)成为784的向量,然后在使用足够深的MLP来进行训练,但是这样造成最直观的结果就是模型的参数会直线上升,因为我的输入足够多,同时为希望模型结果好的情况需要也需要足够深,这样造成训练过程的计算开销是巨大的。(这是很直观的,但是理论上这样训练出来的网络会非常好。可能是这样?)
为了弥补算力的不足,需要寻找新的方式?分析图像识别中目标我们会看出具有两个基本特性:
平移不变性translating- invariance,不管检测对象出现在图像的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应
局部性locality,神经网络前几层应该只探索输入图像中的局部区域,而不是过度在意整个图像其他区域的关系
同时在信号处理中我们也有会滤波器的概念,其基本思想是利用像素之间变化的趋势来进行处理,比如中值滤波可以降噪、利用差分可以识别图像轮廓
image-20220916214004258
我们可以看出卷积的操作是有效的,同时使用(3,3)的filter来对(28,28)的图像处理最终得到(26,26)的图像,执行的操作次数仅为26*26.会让参数数量下降
1.2 卷积的实现(互相关运算、填充padding、步长stride、多通道) 具体公式就不再这里展开,dddd。
经过下列的二维卷积操作会将(n,m)经过(k,k)转换为大小(n+1-k,m+1-k)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Conv2D (nn .module ): def __init__(self ,kernel_size ): super().__init__() self.weight=nn.Parameter (torch .rand (kernel_size )) self.bias=nn.Parameter (torch .zeros (1)) def forward(self ,x ): return corr2d(x ,self .weight )+self.bias def corr2d(X ,k ): ‘’‘计算二维互相关运算``` h,w=k.shape Y =torch.zeros((X .shape [0]-h +1,X .shape [1]-w +1)) for i in range(Y .shape [0]): for j in range(Y .shape [1]): Y [i,j]=(X [i :i +h ,j :j +w ]*K ).sum() return Y
直接进行卷积操作可以看出向量是会变化的,我们还会有两种操作:填充padding和步长stride。
针对二维的图像边缘,我们通常需要设置填充padding来保留周边信息,通常是填充0
(n,m)经过(k,k)后,填充p,得到的结果为(n+p+1-k,m+p+1-k)
针对清晰度不够的照片,我们可能认为其中部分像素冗余,因此可以利用步幅stride来降低采样
(n,m)经过(k,k)加上p之后s的输出是((n+p-k+s)//s,(m+p-k+s)//s )(向下取整)
在二维基础上,理解多通道卷积,首先是多通道输出一个的情况,就是设计三个卷积核然后相加
然后多通道输入对应多通道输出,就是设计output*input个卷积核,然后output的卷积核相加即可
1.3 CNN与深度之间的关系(感受野 receptive- field、汇聚层pooling) CNN中感受野的问题,对于一个(3,3)所感受的是一个(3,3)的区域,但是如果再有一个(3,3)他所感受的就是(5,5)的区域。因此随着卷积层数的增加,卷积神经考虑到的值是越来越大的。
image-20220916215637261
这里也会存在一个trade-off,我们希望卷积的结果感受野不会太小,这样我可以得到一些纹理信息,但是我们也不希望感受野太大,不然所训练出来的CNN会对输入敏感,因此在常见的操作中我们会使用汇聚层来对卷积结果进行平滑或者重新采样。
0x02 Program structure analysis with PyTorch API 2.1 代码整体框架分析(尽可能解耦) 首先神经网络的训练必然是需要多个epoch的,同时在每轮epoch中由于物理空间的限制,我们需要设置batchsize来分批的将数据送入网络,当所有的batch走完说明我们完成一个epoch,这个时候需要记录训练损失(train-loss),训练精度(train-acc)和验证精度(valid- acc)。所以步骤分为:
第一部分 输入:原始数据集,batchsize 输出:训练数据集(可迭代形式)、验证数据集(可迭代形式)
第二部分 输入:网络结构、学习率lr 输出:网络结构net、损失函数loss、优化算法trainer
第三部分 输入:epoch数量num- epoches,训练数据集、验证数据集、net、loss、trainer等 输出:训练好的网络,评估指标
2.2 PyTorch高效API 这个看官网,或者看别人的代码多悟就行
加载数据集 dataset dataloader 定义网络 torch.nn.module Torch.nn.sequential 访问与初始化参数 net.apply()
def init_weigths (self)
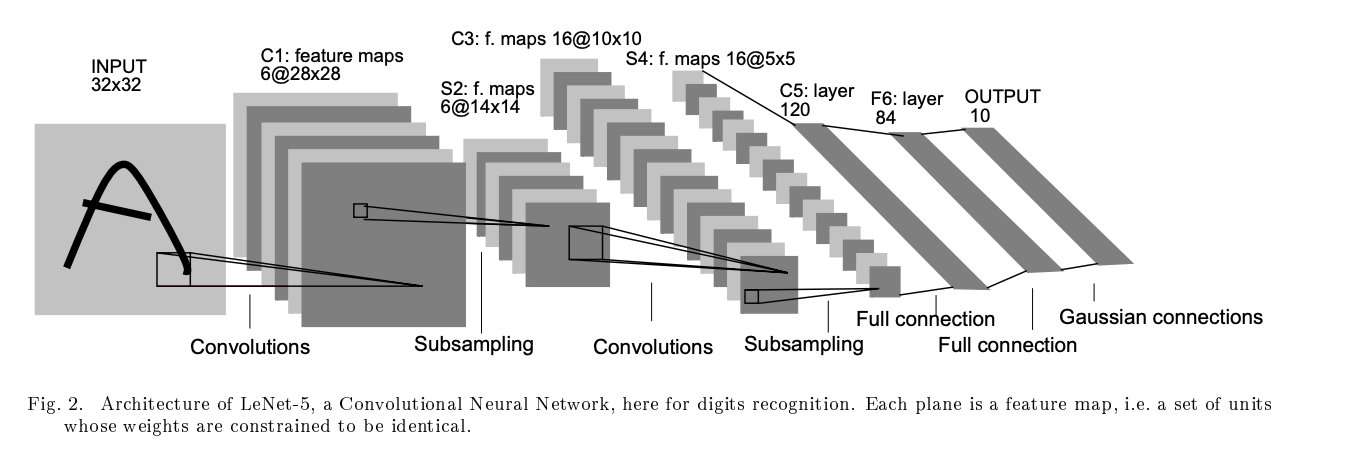
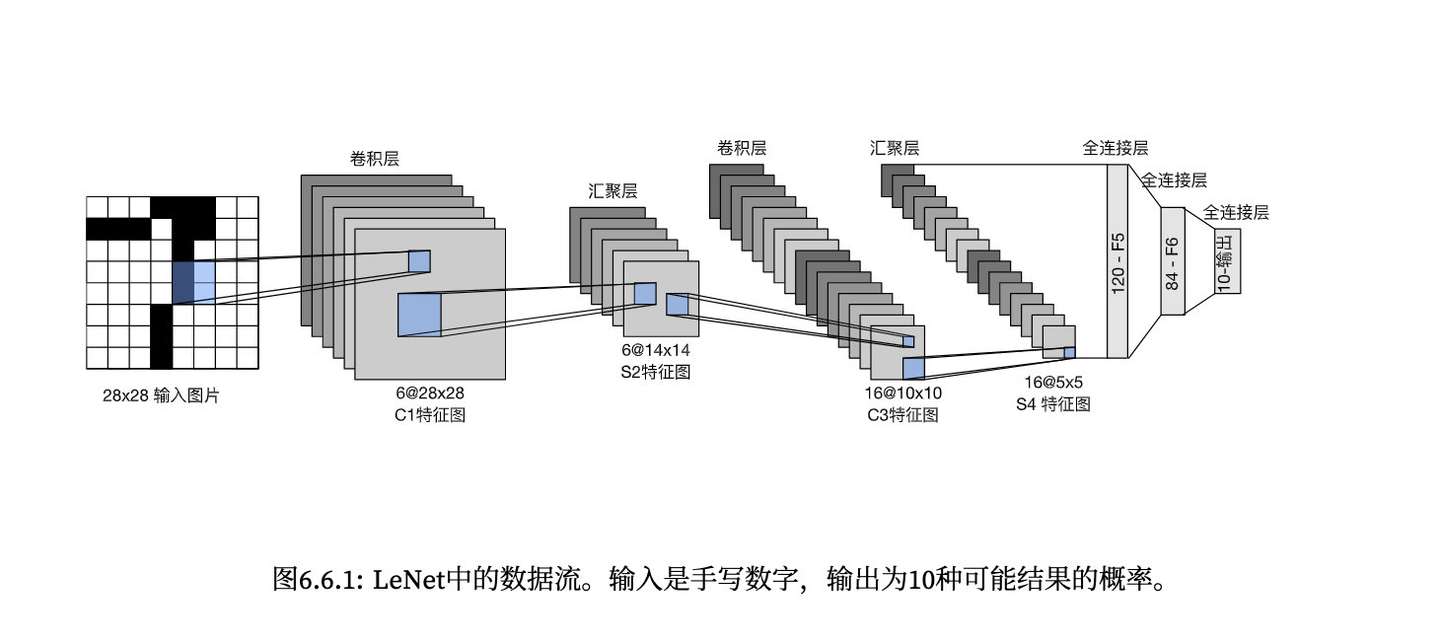
0x03 Code of LeNet LeNet是最早发布的卷积神经网络,起源于89年,在当时还没有强算力的时代,被广泛应用于ATM机器中,帮助处理支票中的数字
image-20220916222118334
这里因为Fashion-MNIST是(28,28)的数据集,因此在这个基础上稍微更改一下
image-20220916222329819
各层参数设置:
输入:(28,28) 第一层:(5,5)卷积,输出6通道,填充=2 ->输出(6,28,28) 第二层:(2,2)池化,步长=2 -> 输出(6,14,14) 第三层:(5,5)卷积,输出16通道,->输出(16,10,10) 第四层:(2,2)池化,步长=2 ->输出(16,5,5) 之后展平
3.1 数据集获取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 读取fashion数据集 def load_fashion_mnist(batchsize):import torchimport dataimport torchvisionimport transformsToTensor ()FashionMNIST (root='../data /FashionMNIST' ,train=True ,transform=trans,download=True )FashionMNIST (root='../data /FashionMNIST' ,train=False ,transform=trans,download=True )data .DataLoader (train_mnist ,batch_size =batchsize ,shuffle =True ,num_workers =4)data .DataLoader (test_mnist ,batch_size =batchsize ,shuffle =True ,num_workers =4)batchsize =256 train_iter ,test_iter=load_fashion_mnist(batchsize)
3.2 模型定义 1 2 3 4 5 6 7 8 9 10 11 12 import torch from torch import nnnet =nn.Sequential(kernel_size =5,padding=2),nn.Sigmoid(),kernel_size =2,stride=2),kernel_size =5),nn.Sigmoid(),kernel_size =2,stride=2),*5 *5 ,120),nn.ReLU(),
3.3 训练过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def accuracy (y_hat,y):len (y_hat.shape)>1 and y_hat.shape[1 ]>1 :argmax (axis=1 )type (y.dtype)==yfloat (cmp.type (y.dtype).sum ())gpu_acc (model,data_iter,device=None):0 0 isinstance (net,nn.Module):eval ()next (iter (net.parameters ())).deviceno_grad ():isinstance (X,list):to (device) for x in X]to (device)to (device)accuracy (net (X),y)numel ()trainer (net,train_iter,test_iter,num_epoches,lr,device):'' '用GPU训练模型' '' init_weights (m):type (m)==nn.Linear or type (m)==nn.Conv2d:xavier_uniform_ (m.weight)normal_ (m.weight,std=0.01 )apply (init_weights)print ('training on' ,device)print (torch.cuda.get_device_name (0 ))to (device)SGD (net.parameters (),lr=lr)CrossEntropyLoss ()range (num_epoches):0 0 0 train ()enumerate (train_iter):zero_grad ()to (device),y.to (device)no_grad ():accuracy (net (X),y)net (X)loss (y_hat,y)backward ()step ()0 ]numel ()append (float (temp_train_acc/num))append (gpu_acc (net,test_iter))append (float (loss_epoch)/num)print ('本轮{}训练的结果,test—acc:{},train-acc:{},train-loss:{}' .format (str (epoch+1 ),str (test_acc[-1 ]),str (train_acc[-1 ]),str (loss_epoches[-1 ])))plot (list (range (1 ,1 +num_epoches)),test_acc,label='test_acc' )plot (list (range (1 ,1 +num_epoches)),train_acc,label='train_acc' )plot (list (range (1 ,1 +num_epoches)),loss_epoches,label='loss' )legend ()show ()0.2 ,20 device ("cuda:0" if torch.cuda.is_available () else "cpu" )trainer (net,train_iter,test_iter,num_epoches,lr,device)
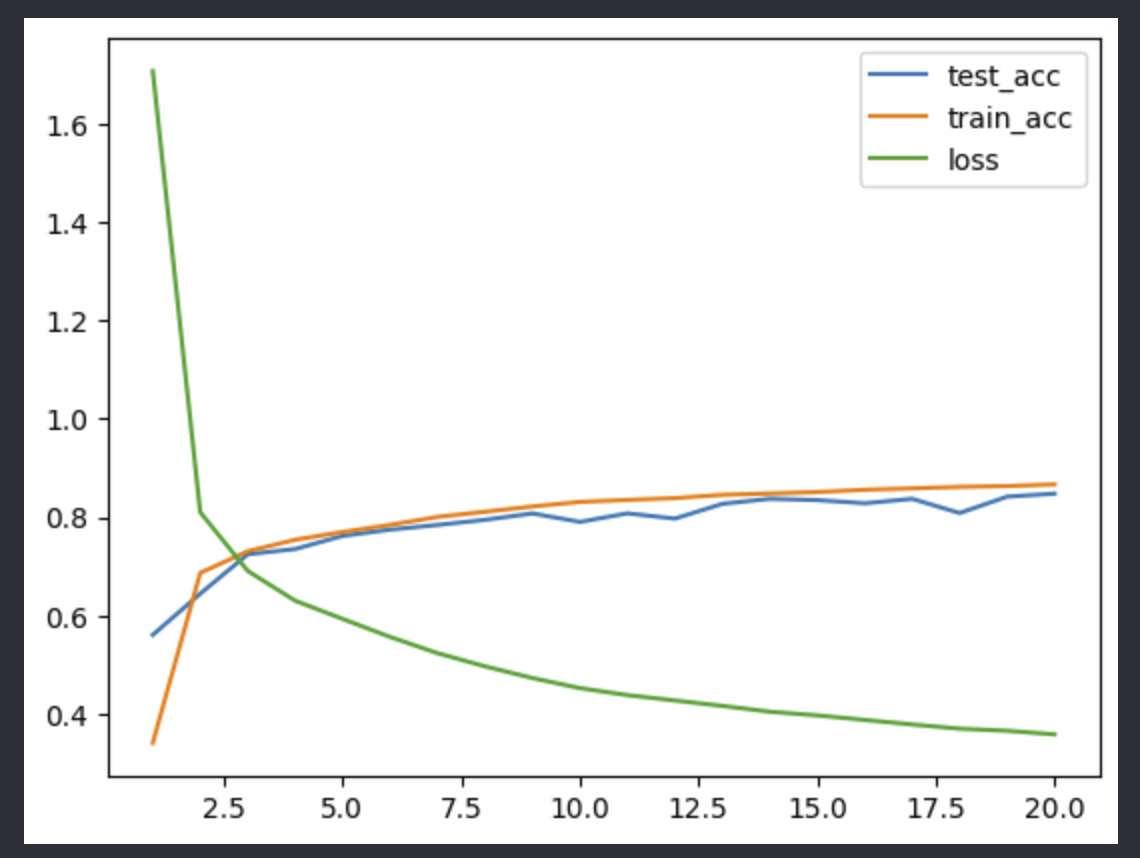
3.4 训练结果 (秀一下3090~)
image-20220916222831979
image-20220916222841744
CS229中关于模型选择中的bias- variance trade off在这里依旧适用
0x04 Discussion and conclusion 4.1 module和sequential之间的区别? What is difference between nn.Module and nn.Sequential
使用module定义模型的时候,我们需要额外def forward,对于卷积神经网络这种按照顺序的结构并不需要关心,所以前向传播是按照sequential进行的,但是在后面的学习中更现代化的CNN或者RNN等会进行输出的迁移,这个时候使用module会更好
4.2 归一化 normalization和标准化standardization之间的区别? 不太懂,先留着
可以参考这个
还有这个
4.3 如何写出规范的代码? 多看别人的代码
看完自己敲出来
4.4 为什么loss会大于1 虽然说看loss只需要下降就好了,但是还是不太明白为什么在mean之后还是大于1
在手敲出来上面的代码能够清晰的感受到,工程对于软件构建的重要性,可能需要先做规划?了解好API才能用别人的抽象好的工具实现更多的功能。虽然这是一个简单的wheel,但是在初始解的基础上可以再次优化