动手学深度学习Vol3 | 经典卷积神经网络实现
在初等卷积神经网络中,我们可以看出从平移不变和缩放不变性质而得到的卷积性质的基础上,在上个世纪诞生的LeNet成功实现与之前不同的路径,在GPU诞生之后,新的网络AlexNet、VGG、NiN、GoogLeNet、Residual Net、DenseNet逐渐发展。卷积神经网络从变深变多,逐渐到变成块以及一些trick的增加。
0x01 introduction
1.1 PyTorch
之前在讲座中听到深度学习框架是深度学习时代的操作系统,怎么说这个比喻有点粗旷但是又不失正确性。个人感觉在计算机时代人们协作的能力达到空前的地步,我们可以上千人共同开发app,这种和建造房屋似的过程充分体现了软件工程的魅力。与土建中规划、设计、建造、 验收等流程相似,个人验证计算机成就的结果是建立在一层一层的抽象的基础上的。
从硬件的角度,现在并不是所有人都需要关心芯片上的三极管,也不需要关心加法器的构成。从之前手工焊机,到芯片的模块化设计,到更高级的抽象工艺和建造工艺的诞生,人们设计更高水平的芯片产生了可能。正是有这些抽象我们才能往前走。
从深度学习框架的角度也是如此,从零实现某个网络在学习过程是有意思的,但是从汇编语言包装成高级编程语言,再包装成一个一个package而形成框架,在前人抽象好的基础上,在深度学习框架搭建的基础上,在使用者的角度更应该重视如何高效的使用。
基于torch构建的PyTorch便是抽象好深度学习的框架。
这里并没有参照 PyTorch官网
而是找到一个开源的 PyTorch中文手册 来了解这个深度学习框架
1 | |
1.2 GPU
这里参照wiki所给的解释:图形处理器GPU解释
图形处理器(英语:Graphics Processing Unit,缩写:GPU;又称显示核心、显卡、视觉处理器、显示芯片或绘图芯片)是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上执行绘图运算工作的微处理器。
GPU不同于传统的CPU,如Intel i5或i7处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU允许某些计算比传统CPU上运行相同的计算速度快10倍至100倍。
1.3 数据集输入和结果计算
1 | |
0x02 经典的CNN
2.1 AlexNet
之前的阅读笔记paper02-2012-imagenet-classification-with-deep-convolutional-neural-networks
主要的贡献,以及后面没有用的地方
- 引入了ReLu激活函数,让训练的更快
- 利用双GPU训练,注意这里对网络结构进行划分(对网络不同层进行切割而不是切割成两种小的部分),工程能力太强了
- (没有用)一种local response normalization,但是确实需要在这个方面做trick,在后面的resNet中可以看到
- (没有用)新的overlapping pooling,一种新的池化方法,这个与双GPU有关
- (有用,但是解释不对)将dropout引入训练过程,尝试解释为ensemble learning,但现在更偏向于regularization
- 数据增强,才有随机抽样数据的方式,将256提取得到224来扩充数据集
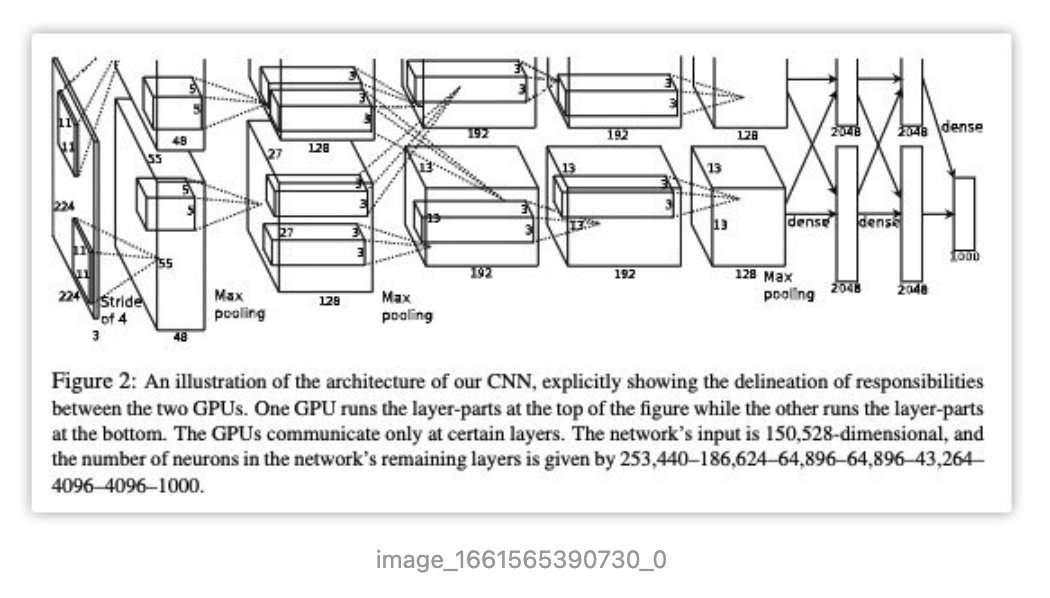
image-20220923164858838
1 | |
2.2 VGG
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
AlexNet证明 #卷积神经网络 CNN convolutional- neural-network 的深度是有效的,但并没有给出模版来进行创建网络。这里一个直觉的想法
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构设计也逐渐变成更加抽象,研究人员开始从单个神经元的角度思考问题,发展到整个层,转向可以复用层的块的模式 #memo
使用 #循环loop 和 子函数 来实现 #VGG
主要做出的贡献
- 利用复用的思路构建卷积块
- 作者尝试各种架构,最终发现深且窄的网络效果是较好的
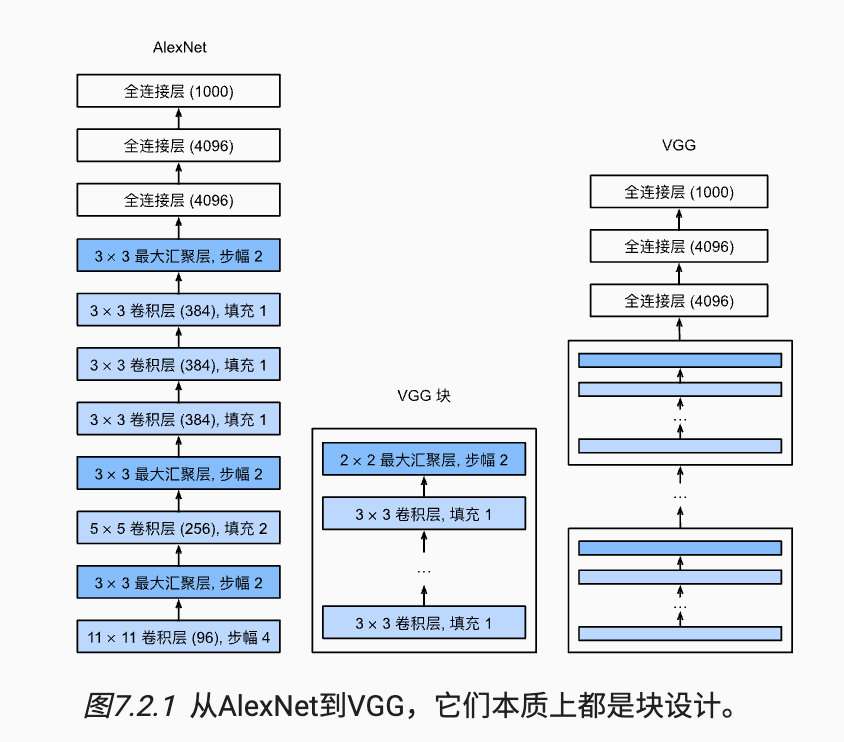
image-20220923165253079
1 | |
2.3 NiN
AlexNet提出使用深度卷积神经网络,VGG给出如何复用的构建卷积神经网络,VGG则是在这个基础上利用MLP对多通道输入和多通道输出进行操作,取代之前简单的加权方式,NiN利用这来对网络的扩大和深度。
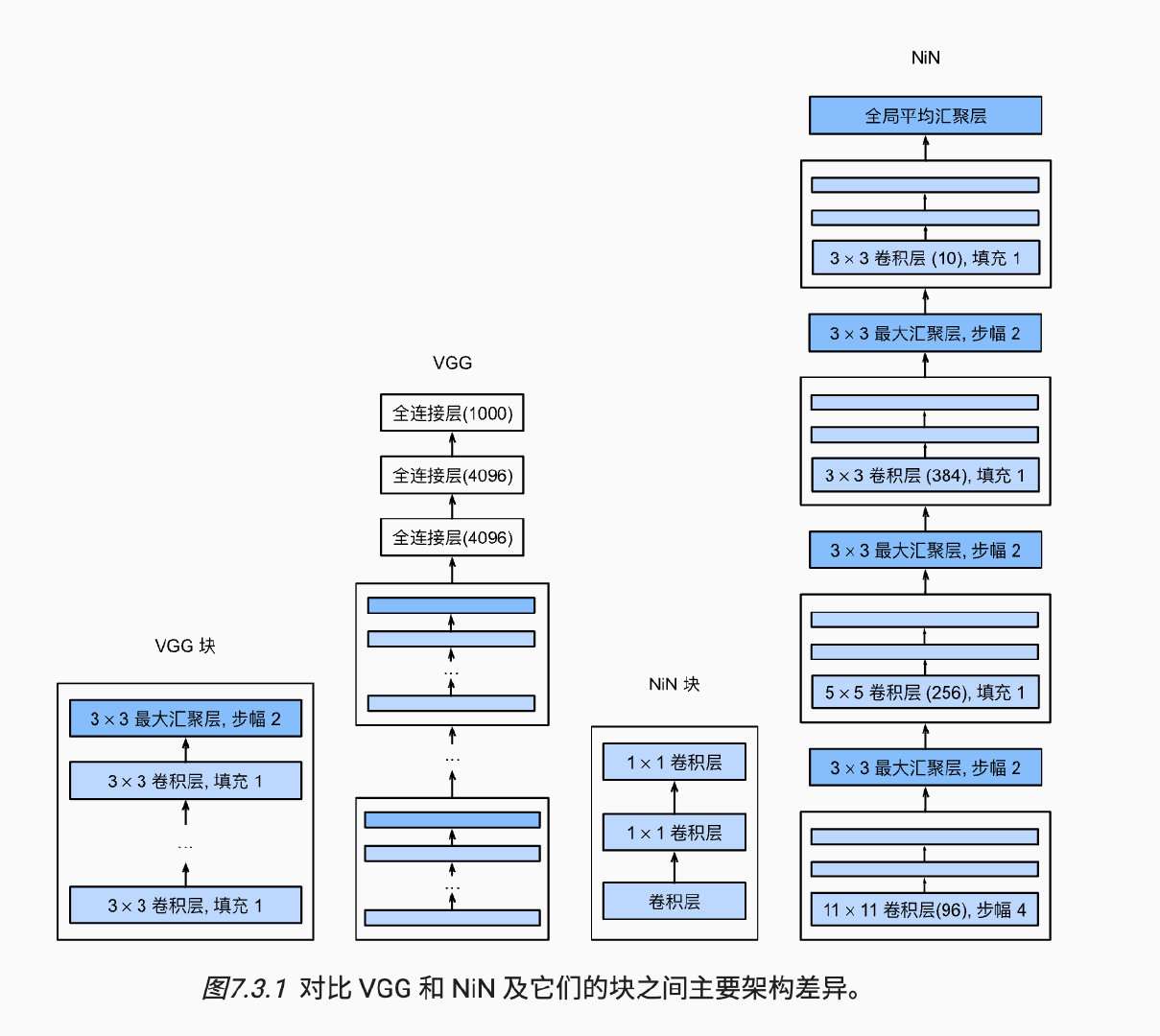
image-20220923165759261
2.4 GoogLeNet
Going deeper with convolutions
GoogLeNet借用NiN的思想,在它的基础上设置来inception块,用来实现多个卷积核对图形特征的提取
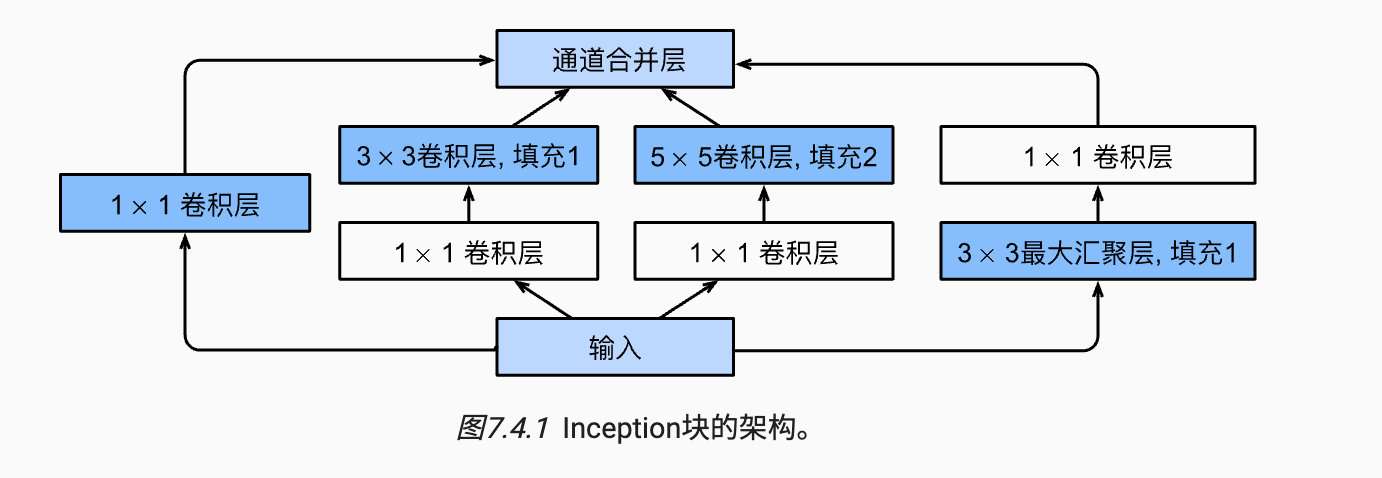
image-20220923165859815
1 | |
2.5 ResNet
Deep Residual Learning for Image Recognition
在之前介绍更深、更广的基础上,resnet更多的是解释如何提高神经网络的性能
部分的数学基础,从学习理论的角度出发,如果模型的复杂程度逐渐增加,这样寻找之前的函数集合的范围是比较大,这样寻找到之后的结果是非常困难的,因此可以尝试将恒等映射转换成为包含数量本身和残差之间的关系
借鉴GBDT中梯度提升的思想,残差问题在现实中往往更加容易优化,同时在模型为理想参数更容易捕捉恒等映射的细微波动,;在实际训练中,残差块中输入可以通过跨层数据线路更快的向前传播
1 | |
2.6 DenseNet
Densely Connected Convolutional Networks
~还没看不重要捏
0x03 Result
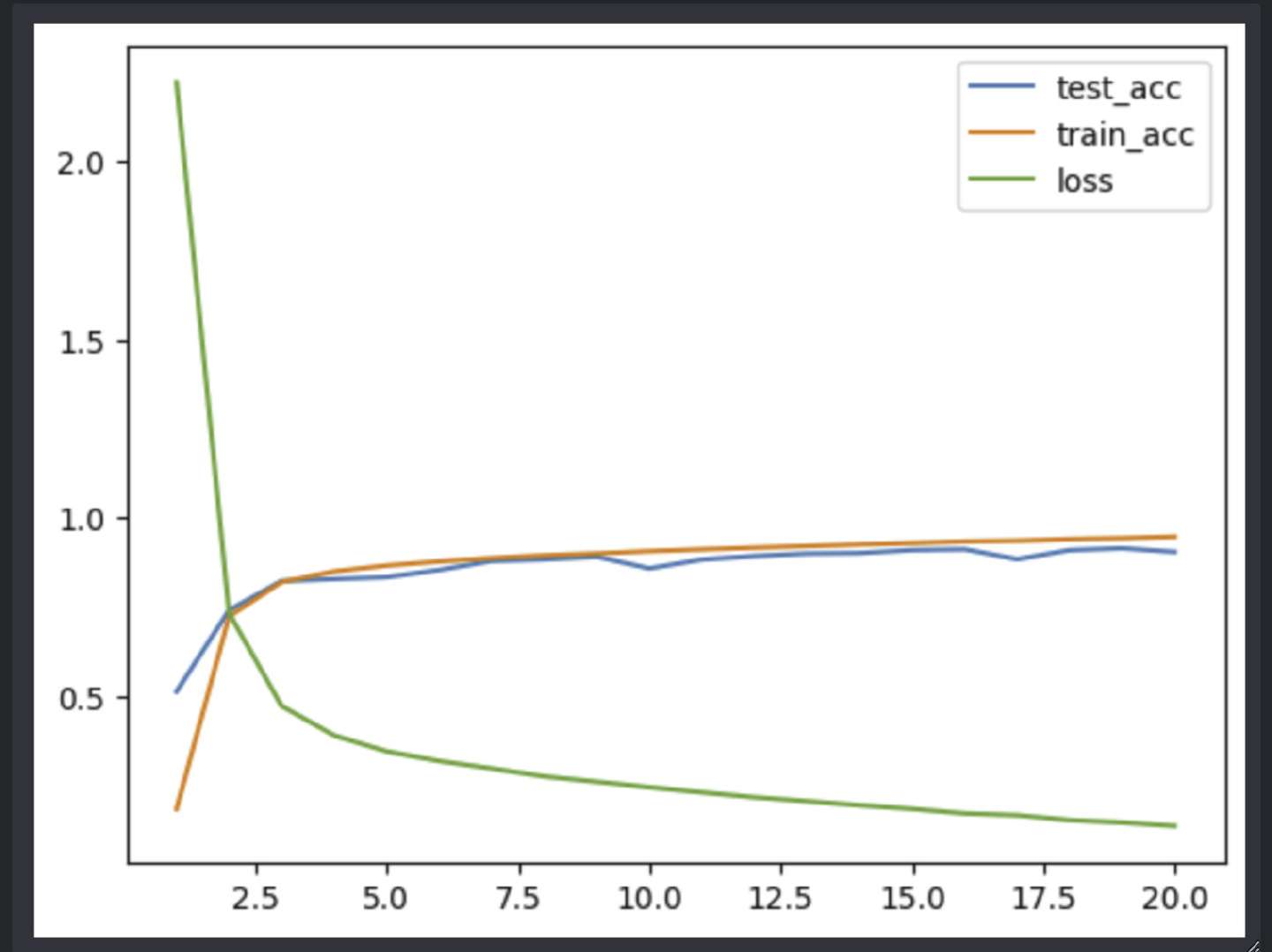
AlexNet
0x04 Discussion
卷积神经网络提取特征的基本在于特征的平移不变和缩放不变,在这个基础上利用互相关操作(错误的被称为卷积)在提取特征。同时在这个过程中围绕了如何构建深度卷积神经网络,主流的blakcbone给出自己自己的发展历史:
- lenet最早给出卷积神经网络的雏形
- alexnet从训练硬件、训练网络、训练数据、数据预处理、训练过程多个方面给出了自己的trick,为后面打下基础
- vgg围绕如何构建更深的网络,引入复用
- nin提出一个trick来构建更广的网络
- Googlenet在nin的基础上,受启发采用多个卷积核提取特征
- 在前人构建好完整的网络的基础上,resnet给出如何保持网络稳定性的方法
- densenet还没有了解
这个过程非常的有意思,可以看到别人是如何前进的。这些都归功李沐老师的总结!