CS285 深度强化学习 Vol4 | 算法分类
Sergev Levine的课讲强化学习我唯一听得懂不同强化学习究竟有哪些分类,同时是如何进行分类的。本次Lecture的目标是完善定义Definition与记号notation,并认清楚RL objective,并给出具体强化学习算法的总结。
0x01 Definition of a MDP
1.1 Recap RL with imitation learning
我们在之前的Lecture02-Supervised_Learning_of_Behavior中认识了Notation,以及imitation learning的局限性,其中最重要的是需要一个专家智能体或者人工来提供数据。但是显然这是不可行的。所以首先我们需要认识到我们的任务应该是什么?或许我们不知道任务具体样子,但我们知道它和我们状态转变序列中的每一步的reward有关。
举个例子,在我们observation=看到红灯的情况下,action=停车往往代表更高的reward,如果action=开车闯过交叉口往往代表负的reward。
0x02 Definition of Reinforcement learning problem
在之前的强化学习-基本概念中已经给出MP、MDP、MRP的定义,这里给出CS285官方对于MDP和POMDP(Partial observation MDP,暂时不讨论)的记号

image-20221024165643496

image-20221024165705565
在强化学习过程中 state-observation- action- state转变中,我们可以将 ()(𝑠1,𝑎1,…,𝑠𝑇,𝑎𝑇) 标记为一个trajectory,不同轨迹的概率可以由下图表示;由于状态s1是随机变量,策略也会输出不同的值,因此这里通常是具有指数的trajectory,因此通常只能用采样的方法来近似的描述总体。
𝑝𝜃(𝜏=𝜏)=𝑝(𝑠1)∏𝑖=0𝑇𝜋𝜃(𝑎𝑡|𝑠𝑡)𝑝(𝑠𝑡+1|𝑠𝑡,𝑎𝑡) 如果我们知道所有可能的轨迹的概率,那么我们就能求解出我们策略对应的期望;很
很不幸的是,在 的概率分布中,我们不知道$s_1$的分布,也不知道状态转移 ;但是我们想确定的是 ;所以我们需要一些知识来做演化,比如我们知道$(s_t,a_t)$是具有MP性质的,也就是

image-20221024165732870
那么我们的奖励期望就可以等价
其中的 表示为状态动作的边缘概率分布。
我们需要做的就是找到它其中的最大值,同样的对于场景中我们会简单的区分为有限场景与无限场景
- infinite horizon case,我们需要最终达到稳定分布(stationary distribution),也就是状态状态不发生改变, ,这时候定义平均回报公式(无折扣)的目标函数为 1.

image-20221024165749396
- finite horizon case ,我们依旧需要 state- action marginal来求解
Question:为什么我们需要期望?
课程中给出的解答是在现实世界中的期望不连续的情况下,通过随机性和期望我们可以将其转变称为连续(smooth)的问题
PS:个人看法除了上述之外,还有一个原因是RL中我们通常希望使用采样Sampling的方法来进行求解,因为我们不可能罗列出所有的可能性,而采样方法得到的往往是期望而不是积分式。因此在RL好的sampling方法也是很重要的。常见的有基于马尔可夫蒙特卡洛MCMC方法,在此基础上蒙地卡罗、重要性采样、基于能量采样、Gibbs采样等等奇奇怪怪的采样方式。
0x03 Anatomy of a RL algorithm
我们可以回顾一下监督学习的范式,对于dataset,我们会有一个假设hypothesis,之后我们可以在dataset中利用learning model来通过loss来optim假设中的param,然后得到我们的model,并可以evaluate。
强化学习中的方式包括
- generate sample,与环境交互或者收集样本来得到基础数据
- fit a model或者estimate the return,我们可以直接拟合一个策略(用神经网络);或者计算轨迹的奖励值(reward?Q?value?)来间接反应好的策略
- improve the policy,无论第二步我们采用的是什么方法,我们的最终目的是需要提升我们的policy

image-20221024165819656
0x04 Brief overview of RL algorithm types
在step2中,我们天然的可以将RL算法分为两类,一类是是直接拟合policy的,一类是根据reward来间接反映policy的好坏。但是reward并不是容易计算的,所以我们会有reward、Q- function或者value - function
4.1 关于评价Policy的好坏
最直接的我们在0x02中已经定义好了,我们来展开计算它:
如果继续写下去,我们会发现其中的“待定“是可以递归的写下去的,直到轨迹的最后,假设我们定义一种函数,名称为Q- function
那么我们的期望奖励就成为
更详细的定义Q- function:
在MRP问题中我们会有一个状态价值的概念,同样我们这里可以由state-value- function,用来反应所有行为下的期望
但是这样得到的Q有用吗?
- (Q- learning)这样我们可以通过改变$\pi_\theta$来改变总期望吗?答案是可以的,我们可以选择对应更大Q值的行为,虽然这不是数学上的描述,但是可以给我们直觉上的可能性。
- (Actor- critic)尽可能选择Q>V的行为,因为V反应这个状态下所有action的平均值
PS:这一段真是太棒了!!!
4.2 Types of RL algorithm
根据第二步fit model我们可以认为是model- based RL,通常包括
- planing;trajectory optimization、optimal control、MCTS
- improve a policy,back propagate gradients into the policy with tricks
- something else,dynamic programming,simulated experience for model-free leaner
- 后面再说
如果是evaluate return,我们可以认为是model- free RL,通常包括
- policy gradients,直接计算Objective和gradient
- value- based,通过平局value- function和Q- function来寻找比较好的方法
- actor- critic,通过评估现在的value function和Q- function,结合PG的想法来提升策略
4.3 why so many algorithms?
模型本身有efficiency- stability;不同的assumption;以及不同问题的使用场景;正如ML中的variance-bias tradeoff,RL中通常是efficiency- stability trade-off
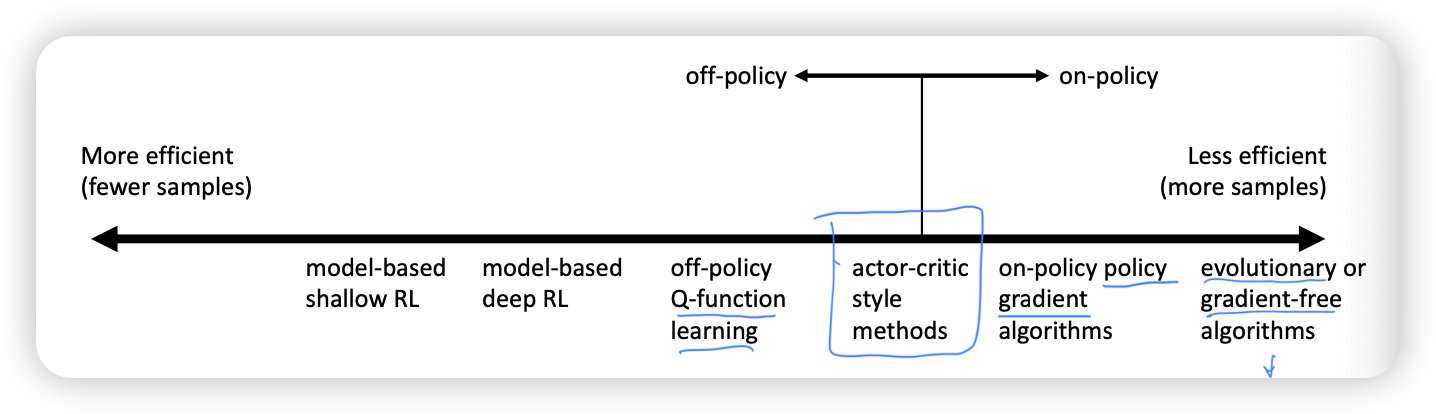
image-20221024165833359

image-20221024165841658
同时不同模型也会有不同的assumption,比如是否全观测,是否连续等

image-20221024165849690
4.4 example of algorithm
具体的分类;后面在具体实现他们吧!
- model- based
- Dyna
- Guided policy search
- model - free
- Policy gradient
- REINFORCE(REward Increments=nonnegative FactorOffset ReinforcementCharacteristic+Eligibility)
- Natural Policy gradient
- Trust region policy optimization
- Value function fitting methods
- Q- learning,DQN
- Temporal difference learning
- Fitted value iteration
- Actor- critic algorithms
- Asynchronous advantage actor- critic
- Soft actor- critic(SAC)