面试经验 vol3 | 从 AB 实验到因果推断
这里参考很多前人的经验:
因果推断笔记——入门学习因果推断在智能营销、补贴的通用框架(十一)-腾讯云开发者社区-腾讯云
基础理论
0. 相关性和因果性
在日常的生活和数据分析中,我们可以得到大量和相关性的杰伦,通常这些相关性和因果性存在对称性,“小偷多的地方,警察多” or “警察多的地方,小偷也会多”,那么是否需要对这个城市增加警力?
因果性往往是存在单箭头的,比如辛普森悖论
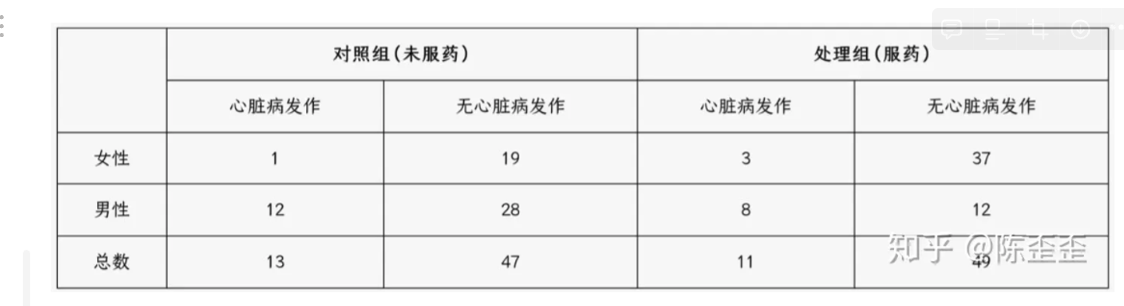
吃药的意愿收到 X 的印象,由此 T 和 X 共同会影响最终的 Y,这和时候需要做分层的解释才能得到最终的结果
1. 解决问题
推理问题的层次包括:
- 关联 association:纯粹的统计关系,在 X 条件下 Y 的输出会怎么样?eg. 购买儿童纸尿裤的人有较大概率会购买啤酒
- 介入 intervention:如果做了某件事情,会发生什么样的效果?eg. 如果我们将地铁票价翻倍会如何?如果吃了药是否会变好?
- 反事实推断 counterfactual inference:如果我们希望 Y 变化,我们希望对 x 做出什么样的改变?eg. 如果地铁人数减少,我们希望知道是否是由票价提高引起的?我们头疼变好是否是因为吃了药
2. 内生性问题
定义:
在线性回归模型中可以定义四个假设:
- 响应变量 y 和解释变量 x 之间存在线性随机函数关系
- 严格外生假定: 当所有时期的解释变量给定时,每一期的随机干扰项的均值都为 0
- 球形扰动假定
- 无完全共线性假定,也就是变量之间不存在线性关系
由此可以得到对应权重变量的OLS 的最优线性无偏估计量,外生性值得是:
E(误差 | 变量) = 0 ,E(误差 t | 变量 t) = 0
如果外生性假定不满足,则会产生内生性问题,常见的问包括
- 遗漏解释变量,存在un observation variable
- X 和 Y 之间互为因果
- 自选择问题
- 测量偏差问题
常见的解决方案包括
- 自然实验法,将其看作是一种实验组和对照组
- 双重差分法 DID,双重差分法,倘若出现一次外部冲击,影响了一部分样本,对另外一部分样本无影响,如果如何外部冲击的影响?可以使用收影响样本做差、未受影响样本做差,差再做差得到最终的结果
- 工具变量 IV,找到影响内在变量的外生变量,连同其他的变量得到最终的结果
- 动态面板回归法,将解释变量和被解释变量的滞后项作为工具变量的方法来进行使用,但是不认可这种处理方法
- 断点回归
- 倾向得分匹配模型 PSM:加权、分层、匹配
关于 PS 问题存在几个误区:
- 没有从根本上介绍因为选择偏差或者遗漏变量造成的内生性问题
- 不能成为 准实验,无法提供模拟实验条件
- 外部有效性条件,在共同支撑假设,PSM 也会排除缺乏对照组的样本进而使得样本代表性变差,影响效果的外部有效性
3. 因果分析的两种框架
潜在结果框架 Rubin potential outcome RCM
希望估计单个个体或者整体平均意义下的 treatment effect:
- 识别(identification)将因果关系从关联中分割
- 估计(estimation)计算因果关系的大小
- 检验(hypo test)我们有多大信心结果是正确的
- 置信(conf int)结果会存在多大的扰动
最重要的是需要找到合适的:对照组和实验组
keywords:
- 匹配方法
- 双重差分模型 DID
- 合成控制法 Synthetic control method
- 断点回归
因果图结果框架 Pearl causal graph CGM
有向图用来描述变量之间的因果关系,通过计算因果图之间的条件分布,获得变量之间的因果关系,希望使用条件分布来消除估计偏差,最核心的估计检验分布,消除其他变量带来的偏差
侧重识别
keywords:后门准则 和 前门准则
4. 调节效应于中介效应
- 中介效应:X —> M —> Y
- 调节效用:X —> Y, M —> Y
比如,性别 X 和录取 Y 之间的关系,其中性别 X 会影响 M 学历,进而影响 Y,这个是中介效用,这个时候我们需要消除这个学历(confounders)的影响来保证学历不变的情况下,衡量性别于录取结果之间的关系
比如,收入 I 会影响M,这个就是调节作用
5. 常见假设
无混淆性 unconfounder | 可忽略假设 Ignorability | CIA 假设
不存在未被观察到的可以影响 T 分布的混杂因子
正值假设 positivity
至少存在一项干预导致的结果是无法被观察饿的
一致性假设 consistency | 稳定单元干预值假设 Stable unit treatment value assumption SUTVA
任意单元的潜在结果都不会因为其他单元的干预发生改变而改变,且对于每个单元其所接受的每种干预不存在不同的形式或版本导致不同的潜在结果
干预水平对于所有的个体一致
常见模型
1. PS based 方法
Match 匹配方法,寻找对照组
IPW 逆倾向性打分的方法
缺点:1. 需要对 PS 估计足够准确 2. 过去趋近于 会导致权重过高
DR or (AIPW)增强 IPW 方法结合倾向性打分和结果回顾模型来得样本权重
Stratification PSS 方法
2. 数据驱动的方法
D2VD 变量分解方法
- 混淆变量 confounders:影响干预变量 T,也会影响结果变量 Y
- 调整变量 adjustment: 与干预变量 T 独立,但是会影响到 Y
- 无关变量,不会直接影响到干预变量于估计变量
3. 平衡性 and 均衡性检验检查
如何知道匹配的效果?或者实验组对照组是否分布均匀
最直观的是观察
- PS 分数在匹配前后的分布,或者是
- 特征匹配前后的 QQ plot
- 量化指标 SMD,用于计算两者之间的差异
- 共同支撑检验 common support:主要检验的目的是确定针对每个处理组,都有对照组与之匹配
反驳 Refute
使用不同的数据干预方式来进行检验,来验证得到的因果效应的有效性,反驳的基本原理是对于数据进行某种关于之后,对重新生成的数据进行因果效应的估计
- 安慰剂数据方法,使用 placebo 的方法来代替真实的处理变量
- 随机混淆变量,增加一个随机生成的混淆变量
- 子集数据方法:随机删除一部分数据,作为最终数据的随机自己
4. DID 双重差分法
在一定程度上减轻了选择偏差和外因带来的影响
使用的时候需要满足的假设:
- 线性关系假设:来自于线性回归,认为因变量和结果变量存在线性关系
- 个体处理稳定假设 SUTVA
- 一致性 consistency:个体接受处理所导致的潜在结果是唯一的
- 互不干预:个体接受处理的潜在结果不会受到其他个体吃的影响,eg 比如我在淘宝上购买红包后会更愿意买东西,并不会因为我同事也领到了红包而降低意愿
- 平行趋势假设:结果的趋势是一只的
5. 工具变量法 Instrumental variable
工具变量需要存在以下三个条件
- Z 和 T 相关
- Z 只能通过T 影响 Y
- Z 和 Y 没有共同诱因
6. Double machine learning
消除精准预测,使用任意的 ML 模型给出特征对于目标的无偏估计
应用细节
1. 双重机器学习 Double machine learning
问题例子:分析直播推荐多样性(D)对用户活跃度(Y)的影响,都收到用户自身的画像、用户过去的直播浏览历史 X 有关
存在的问题:
- X 的纬度太高怎么办?
- 不知道 X 和 D 的关系
方法思路:
- CIA 假设,所有混淆变量都可以被观测
- ML 自带的正则化来达到高纬度变量的选择的目的
估计 X 对 Y 的影响,再估计 X 对 D 的影响,提出这两部分之后,取残差进行估计,来分析直播多样性和输出之间的关系
2. 因果随机森林模型
相当于训练一个 treatment 的树,然后在树的节点做因果头对岸,类似于match or subclass很相似
3. meta learner 对于 uplift modeling
S-learner
T-learner
X-learner:利用 weight function 来得到两种不同 ATE 估计的求和
4. 快手的因果推断和实验估计
场景:直播是一个双边网络
网络设计的难点:网络效应的检测和应对
- 流量扶持情况下,主播是否存在流量基站
- 主播侧传播到用户侧的双边网络效用
- 用户侧传播到主播侧的双边网络效用
更微观一点的:
问题挂件是否会存在刺激消费?
主播:control 不上挂件、treatment 上挂件
用户:control 看不到挂件、treatment 看得到挂件
- 挂件可能会导致 treatment用户在 treatment 和 control 的用户之间转移直播消费
- treatment 主播可能会更加卖力直播,影响 treatment 和 control 组观众
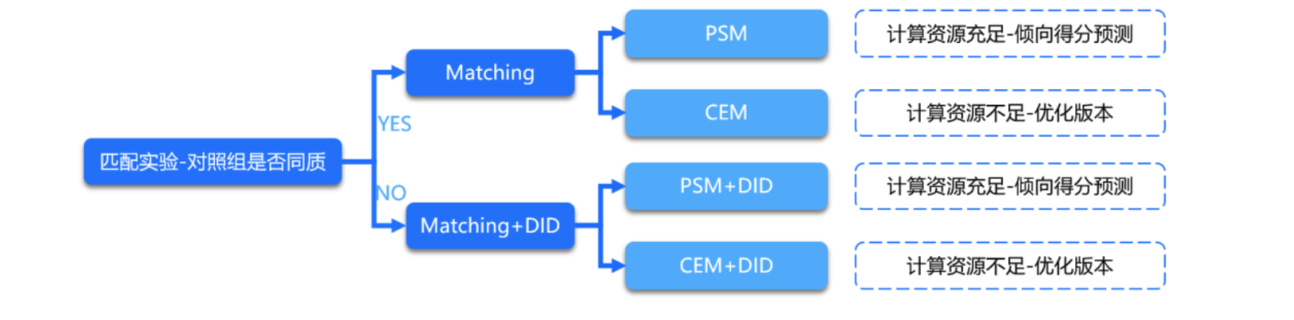
5. 淘宝中的PSM+DID
实验组和对照组是否同质
PSM: 根据倾向性打分来进行匹配,适用于样本属性很高,并且不好做切断的离散变量
CEM:广义精确匹配,使用核心混杂因子进行匹配,每个实验用户匹配到的 N 个同特征用户作为对照组,取 N 个同特征用户的核心指标均值作为实验用户的对照
6. 淘宝3D 化价值分析
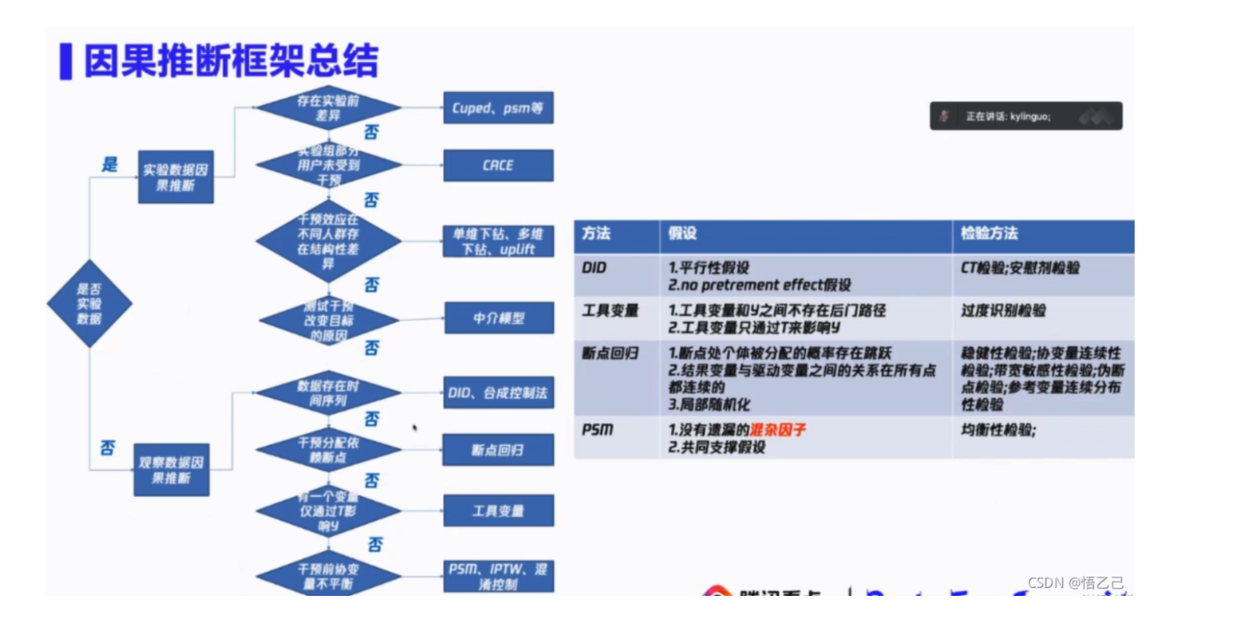
7 腾讯因果推断框架总结
8. 滴滴国际化外卖团队的因果推断
因果推断建模和 auuc
ROI = (指标|干预 - 指标|不干预)/ (补贴|干预 - 补贴|不干预)
ROI 不一定会是一个好的指标,同时 GMV 和成本分层下对应的ROI 提升也是有效的
9. QQ 浏览器 push 优化实践
 个人总结
个人总结
离散选择或者一类的回归分析、基于特征重要性的树模型是从 结果来分析对应的原因,这个其实和因果推断中得出 AB 实验如何来分析背后的差异是一致的,本质上解决的问题是从结果到原因
- 改不改发优惠卷
在因果推断方法中,我们希望解决what if 的问题,也就是从如果我们希望得到什么样的结果,我们应该如何来做出自己的策略的选择,这个是从“原因来分析结果”,所以通常有因果关系发现和因果效用估计两种方式
- 线路关闭受到哪些影响因素
- 指标异常分析、流失分析、DAU 分析
那么为什么要做因果推断?这个表现在强化学习中是可能会造成智能体学习的策略估计,通常最简单的方式是DQN 的 Q 值会过高轨迹,为了解决这个 on policy 的问题,我们通常会使用 off policy 的方法来分离探索智能体和目标智能体来得到教优估计。