CS285 深度强化学习 Vol8 | Q 函数
从Policy gradient,到Actor- critic,我们尝试丢弃policy,从AC到Q- iteration或者Q- learning我们彻底丢弃Policy,但是遇到不能收敛的问题。现在我们尝试改进Q- learning来实现想要的功能
0x01 Q- learning中的问题
上次从理论的角度看出online Q iteration很难收敛,更直观的看待问题我们会发现有以下几点的原因:
- Q- learning中通常使用的是单个样本,这样对于更新迭代并不友好
- 在第三步中的有一个类似gradient descent的公式但是其实在同一个轨迹中两者之间具有强烈相关性
- 不满足iid假设样本中的效果并不好

image-20221102223452106
解决思路
- 修正样本,同样借鉴AC中的方法可以使用synchronized parallel Q- learning或者asynchronous parallel Q- learning来实现。
- 使用replay buffers,因为Q- learning只需要(state,action,next- state,reward)就行

image-20221102223917061
0x02 Q-learning with replay- buffer的问题
按照厂里后面的一部份应该是没有梯度的,但是因为两者具有相关性我们的效果会很差,起不到梯度下降的效果。

image-20221102224124136
因此我们会设置一个target network,在每次更新的时候,target也不会改变,同时这个过程中两者是某种意义上的不想关的。背后的方式是启发式的,但是实际上是一种经验很好的实践方法。通常更新的时候可以用指数平均的方法

image-20221102225023533
更高的视角
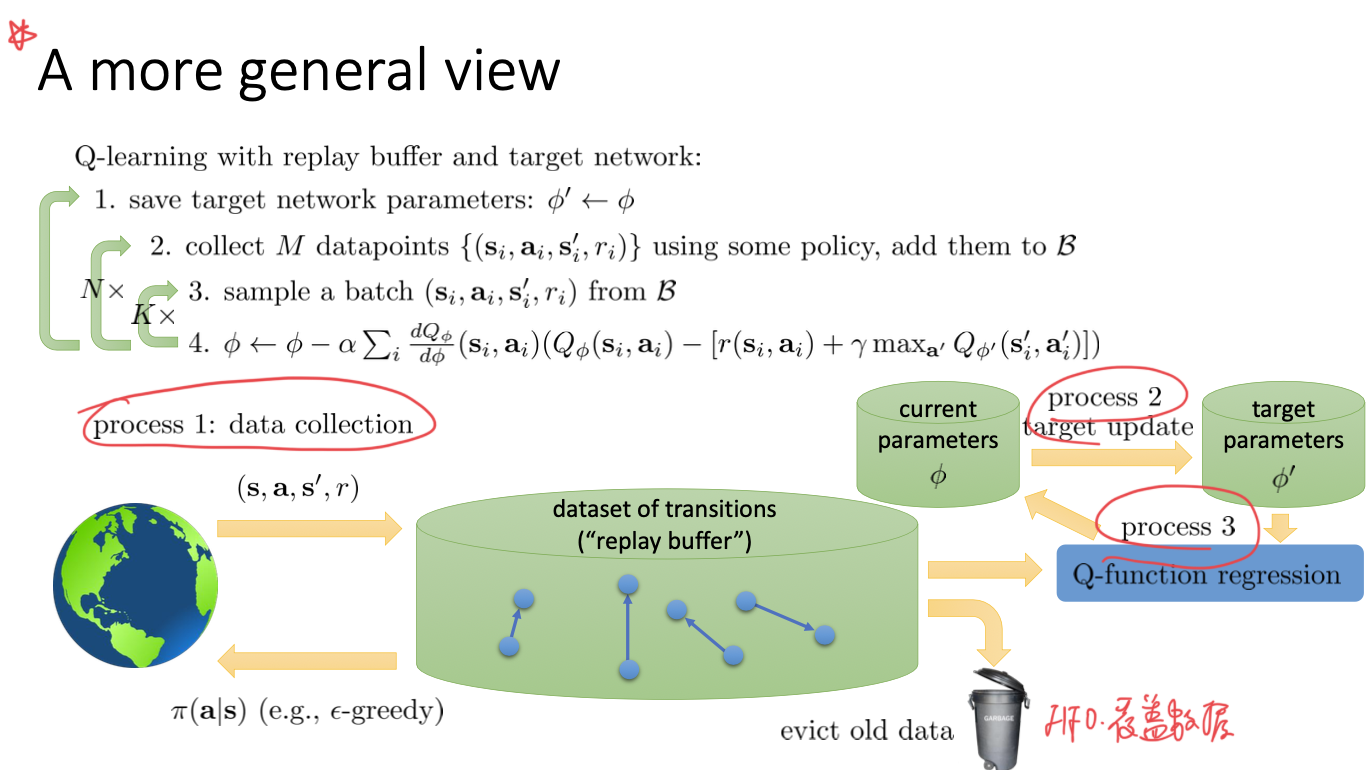
image-20221102225216215
0x03 提高Q-learning
后面结合一篇论文来介绍,也就是Rainbow~
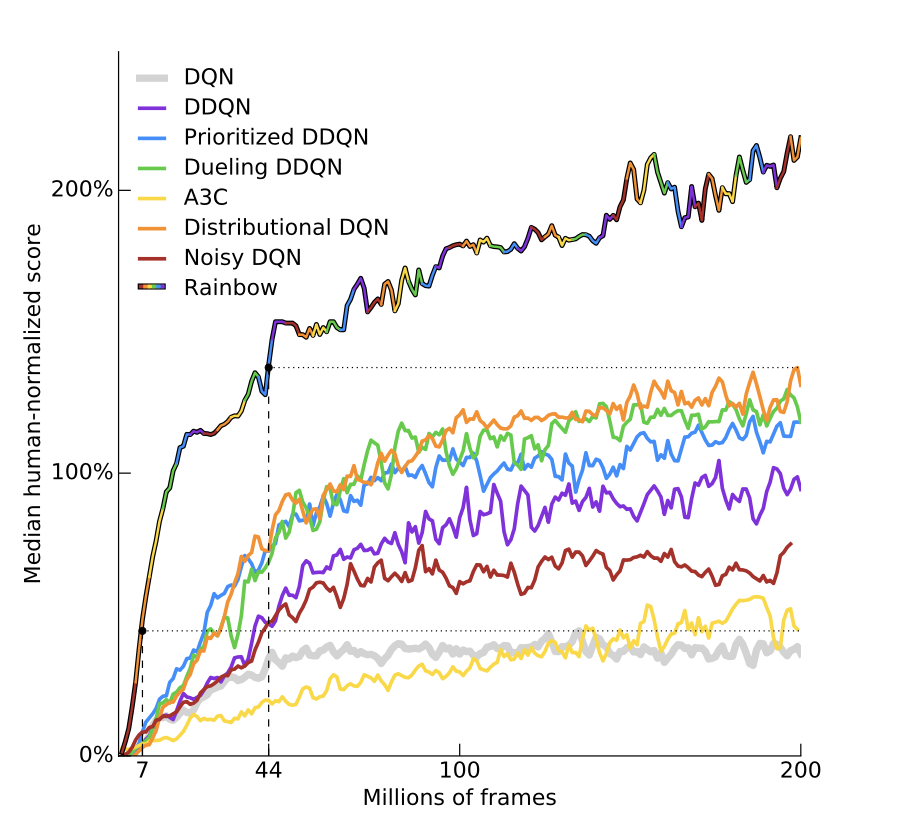
image-20221102225350693
CS285 深度强化学习 Vol8 | Q 函数
https://blog.tjdata.site/posts/7e704bf4.html