回顾说明是基于树的集成学习,同时给出基本的随机森林和Adaboost解释,以及GBDT的两种工程实现XGboost和lightGBM的介绍,并用实际的Kaggle例子解释使用。
0x01 树(Tree)与集成学习(Ensemble learning) 1.1 什么是决策树 在之前的文章已经提到过 决策树CART与手撕代码 ,决策树是一类基于分治思想的非参数的机器学习方法。通过自上而下的树形拆分对数据进行分类,作为一类最简单的最基础的监督学习模型可以被用于分类和回归问题。决策的过程分为
特征选择
树的构造
树的建枝,为了避免过拟合
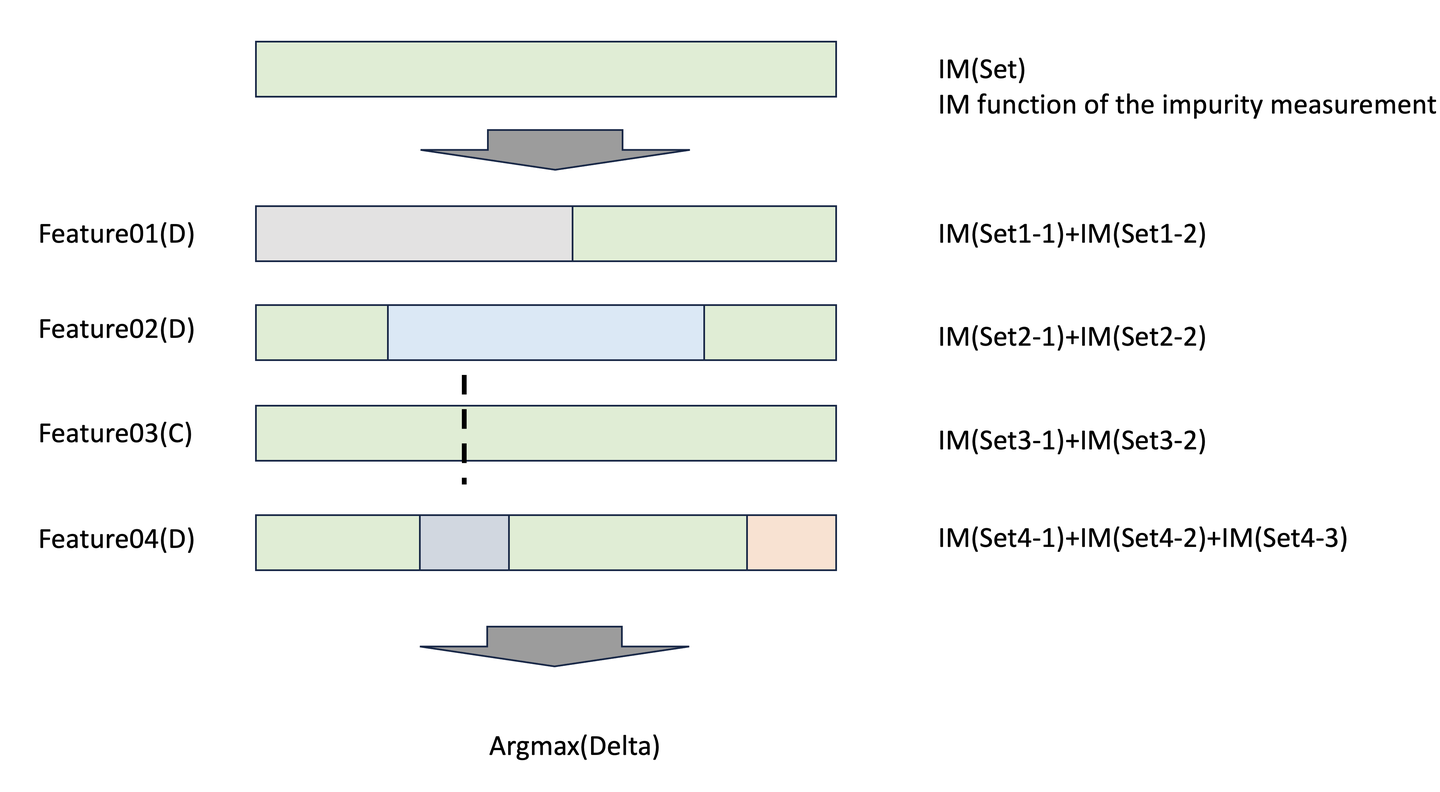
所谓构造准则是在选择分支的时候如何确定规则取值?我们可以使用某种不纯度(Impurity)度量方式,来比较分支前的集合和分支之后子集度量之和来选择不纯度下降最大的特征作为区分。
特征选择过程
ID3
最大信息增益
倾向于选择取值多的特征;对样本缺失值敏感
离散,分类
C4.5
最大信息增益比
对于ID3的正则化,避免选择取值多的特征
离散连续,分类
CART
Gini或者最小平方差
最终形成二叉树
离散连续,分类和回归
1.2 什么是集成学习 在之前的 学习理论 — 集成学习 中我们介绍了我们可以尝试训练不同的模型并将他们共同输出来得到最终的结果,潜在的假设在于集成多个训练的结果可以达到超过原有单个模型的效果。其中集中方式主要分为:
使用算法训练得到不同的模型
将不同模型输出的结果通过平均、投票或者学习(Stacking)的方式来得到(MOE)
在学习规则中使用不同的策略集中,Boosting(串行)、Bagging(并行)
这里主要解释两种不同的策略
Bagging,主要是设计不同的基训练模型,对于同一个训练集我们如何训练得到不同的模型?一种简单的方式是分割数据集,但是这样对于样本的利用率并不高。是否存在一种方式可以重复利用样本但是不同学习器之间存在训练分布的差异。这个时候可以使用之前在模型评价中的自助采样(bootstrap)方法来选择不同的数据样本或者选择不同的特征。
Boosting,主要是将上一模型的输出继续进行学习,有点类似残差学习的概念,或者resent的想法来弥补之前算法的缺陷,在其中通常是设计如何选择之后采样的权重。
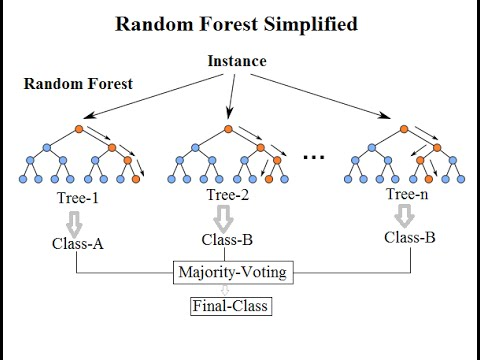
1.3 随机森林和AdaBoost 给出两种不同的例子,一种是基于Bagging的随机森林
随机森林
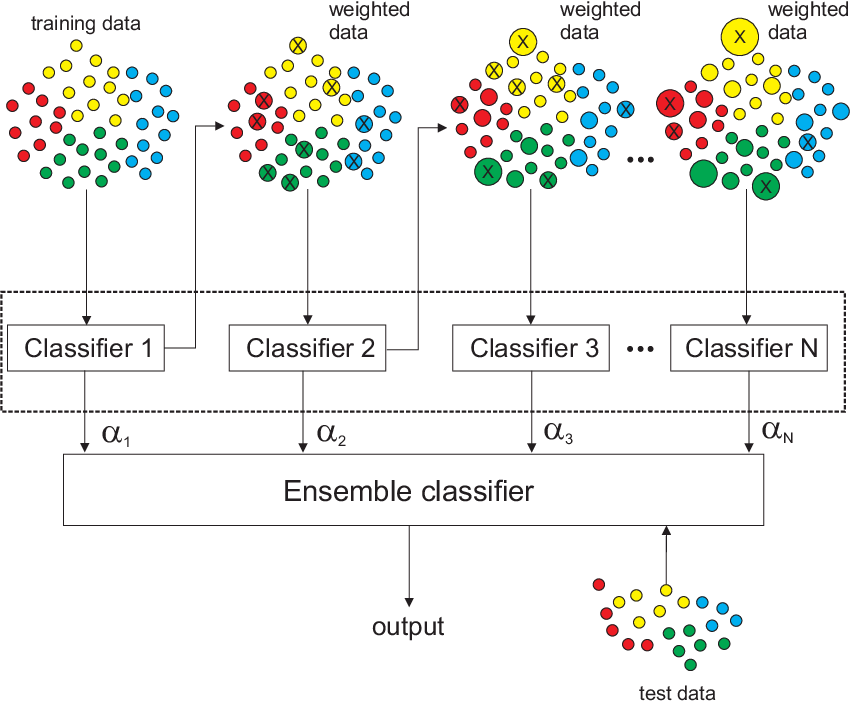
一种是基于boosting的Adaboost,通过输出错误分类数据的权重来影响下一个决策树的学习
Adaboost
Adaboost伪代码
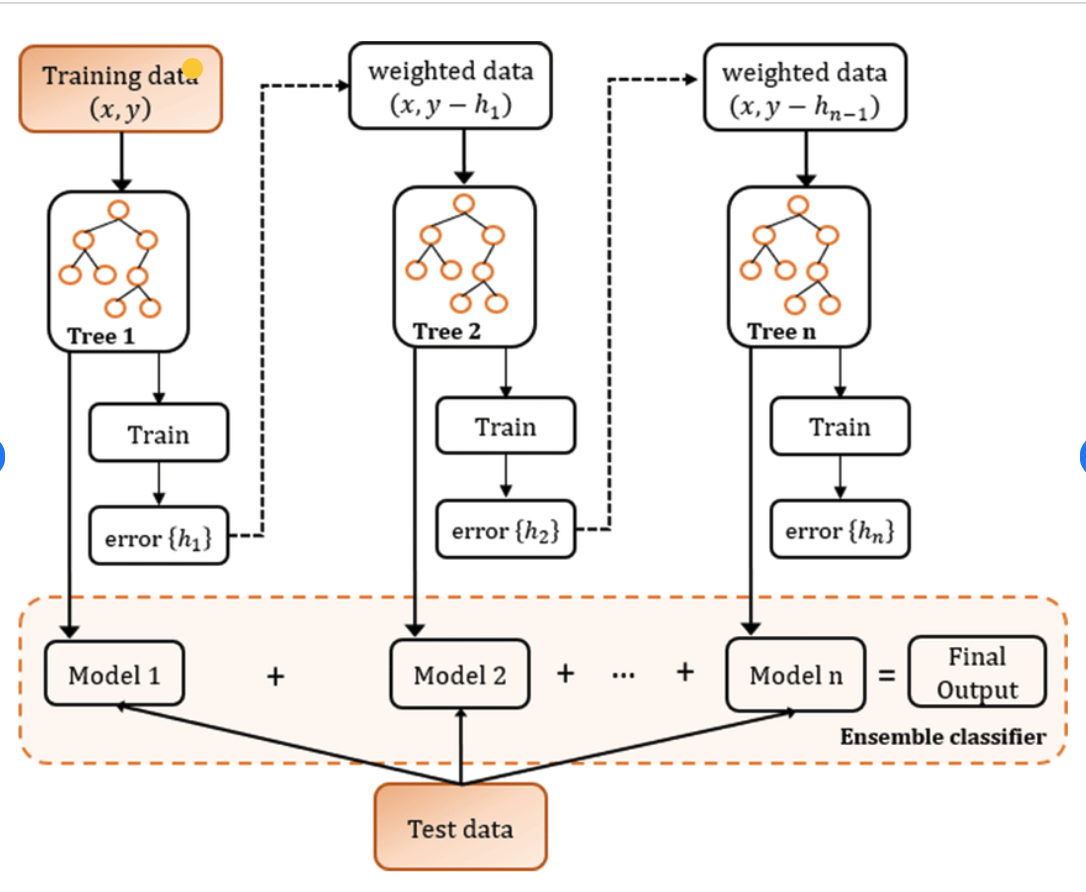
0x02 梯度提升树(Gradient boosting tree) 2.1 什么是梯度提升树 梯度提升(Gradient boosting)是一类方法,思想主要是使用残差进行下一段的学习,最终的结果为所有的树的结果加和。其是基于经验损失函数的负梯度来构建新的决策树,同时在决策树构建完成之后进行剪枝
Boosting模型:GBDT原理介绍| 机器学习算法技术分享
Gradient boost
1 2 3 4 5 6 from sklearn.ensemble import AdaBoostClassifierAdaBoostClassifier (n_estimators=len (X_train),random_state=42 ).fit (X_train, y_train).predict (X_test).metrics import accuracy_scoreprint ('Accuracy: ' , accuracy_score(y_test, y_pred)
2.2 Xgboost 作为GBDT工程化的行驶,相比较GBDT直接使用差分,Xgboost对损失函数进行了二阶泰勒展开,并加入正则化项目来保证整体的最优解,用来权衡目标函数的下降和模型的复杂度来避免过拟合
1 2 3 4 5 import xgboost as xgbobjective ="binary:logistic" , random_state =42)print ('Accuracy: ' , accuracy_score(y_test, y_pred))
2.3 LightGBM 作为另外一种GBDT工程化实现的方式,其具有更快的训练速度、效率、低内存的使用和更好的性能,更容易训练在大型文件夹中。其主要用到了两种非常独特的方法
单边梯度采样,Gradient-based on side sampling,利用数学证明是可行的
不同的数据实例在计算信息增益时具有不同的功能。梯度大的实例(即培训不足的示例)将为信息获取做出更多贡献。GOSS保留具有大梯度(例如,大于预定义阈值或顶部百分位数)的实例,并且仅随机删除具有小梯度的实例,以保持信息增益估计的准确性。这种处理可以导致比均匀随机抽样更准确的增益估计,具有相同的目标采样率,特别是当信息增益值范围很大时。
特征捆绑,Exclusive feature bundling technique
高维数据通常非常稀疏,这为我们提供了设计一种几乎无损的方法来减少特征数量的可能性。具体来说,在稀疏特征空间中,许多特征是相互排斥的,即它们从不同时使用非零值。独家功能可以安全地捆绑到单个功能中(称为独家功能包)。因此,直方图构建的复杂性从O(数据×特征)变为O(数据×捆绑),而bundle<<特征。因此,在不影响准确性的情况下,提高了培训框架的速度。
怎么说呢?这些在使用的过程中通常并不会使用到。其中非常有意思的为了压缩信息,会使用直方图的方式来聚集数据和离散数据。
lightGBM伪代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from sklearn.metrics import log_loss, roc_auc_score'boosting_type' : 'gbdt' ,'objective' : 'binary' ,'metric' : {'binary_logloss' , 'auc' },'num_leaves' : 31,'learning_rate' : 0.05,'feature_fraction' : 0.9,'bagging_fraction' : 0.8,'bagging_freq' : 5,'verbose' : 0print ('Start training...' )num_boost_round =20, valid_sets =test_data, early_stopping_rounds =5)print ('Save model...' )'model.txt' )print ('Start predicting...' )num_iteration =gbm.best_iteration)print ('The logloss of prediction is:' , log_loss(y_test, y_pred))print ('The auc of prediction is:' , roc_auc_score(y_test, y_pred))print ('Plot feature importances...' )title ='Feature importance' , xlabel ='Feature importance' , ylabel ='Features' , figsize=(10, 10))
2.4 解释性 对于tree-based模型最直观的是可以输出树作为最终结果,在树的节点上我们可以给出计算结果,包括:
Feature importance,基于之前的不纯度指标,或者特征节点的分裂次数来计算
Shap,是可以计算出Tree-based模型的系数的一种方法,但是比较麻烦
Null importance,参考统计学中的一个基本假设。如果一个特征被随机数代替之后结果并没有出现明显差异,说明这个特征并没有什么用。称为洗牌(permutation)
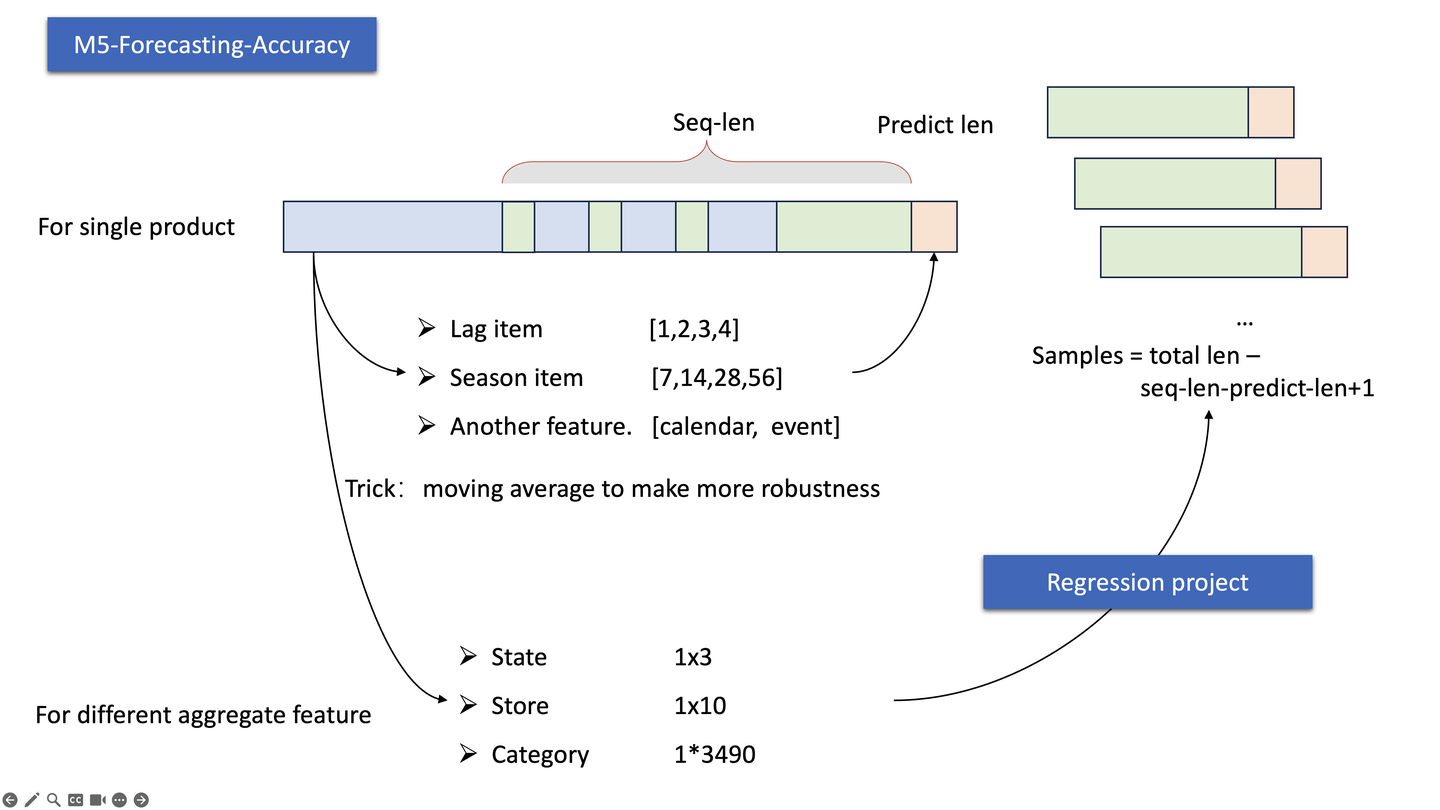
0x03 实例:M5-Forecasting-Accuracy 3.1 问题描述 Kaggle 比赛地址:M5-Forecasting-Accuracy
原始数据项目地址:MOFC
数据主要为美国三个州、十个商店、3490个商品的销售数据,数据描述包括:
日历文件(Calendar),给出week下标、星期、日、月、年、事件1名称、事件1类型、事件2名称、事件2类型、三个州是否允许商品券购买
销售数据(Sales-train),给出每个产品每天的销售量、分类、商品、状态和日期
销售价格(Sell-price),对应日期商品的价格
最终的考核指标除了单个商品销售数量的预测,还包括不同层级聚合后的结果评价(比如三个州商品总和预测精度等等。
3.2 特征工程 首先对于单个商品来看,是一个时间序列处理问题,主要是采用原有数据特征来分析。从销售事件序列上来看我们可以采集滞后项目(Lag)、季节特征(season);从日历中我们可以设计天特征、事件类型等特征;从价格中我们设计价格特征等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns'../../data/m5-forecasting-accuracy/calendar.csv' )'../../data/m5-forecasting-accuracy/sales_train_validation.csv' )'../../data/m5-forecasting-accuracy/sell_prices.csv' )'../../data/m5-forecasting-accuracy/sample_submission.csv' )for c in df_sales_train_validation.columns if 'd_' in c] 1914 7 1 def get_local_features (target_day, predict_distance ):for i in range (local_range):'l_' +str (i + 1 )] = x['d_' +str (target_day - i - predict_distance)].astype(float )'l_' +str (i + 1 ) for i in range (local_range)]return local_features[l_cols]print (get_local_features(target_day,predict_distance))def get_local_accumulated_feature (target_day, predict_distance ):'la_1' ] = x['d_' +str (target_day - predict_distance)].astype(float )for i in range (1 , local_range):'la_' +str (i + 1 )] = x['d_' +str (target_day - i - predict_distance)].astype(float ) +\'la_' + str (i)]'la_' +str (i + 1 ) for i in range (local_range)]return local_accumulated_feature[la_cols]1 ]].cumsum(axis=1 )1 , 2 , 3 , 4 , 5 , 6 , 7 , 14 , 21 , 28 , 42 , 56 ]def get_accumulated_features (target_day, predict_distance ):for distance in used_history_distances:'la_' + str (distance)] = tx['d_' + str (target_day - distance - predict_distance + 1 )].astype(float )'la_' + str (distance) for distance in used_history_distances]return long_term_features[la_cols]def get_period_sale (target_day, predict_distance ):7 1 ) // periodfor i in range (8 ):'p_' +str (i + 1 )] = x['d_' + str (cur_day)].astype(float )return period_saledef get_period_features (target_day, predict_distance ):1 )return tx_perioddef get_history_features (target_day, predict_distance ):return pd.concat([get_accumulated_features(target_day, predict_distance),1 )
特征构造思路
3.3 训练与调参 默认参数包括
估计类型boosting: ‘gbdt’
学习模版objective:‘regression‘
评价指标metric:’rmse‘
由于集成模型中的参数比较多,调参力度可能比较大。以lightGBM的params为例子,参考知乎中的文章,可以使用
经验参数:学习率(learning rate)、集成的迭代次数(n_estimator)、节点分裂的最小增益(min_split_gain)、叶子上最小数据量(min_child_sample)、叶子上最小的hessian和(min_child_weight)
模型最大的深度(max_depth)、叶子节点数量(num_leaves)、正则化参数(reg_alpha,reg_lambda),数据采样(subsample or bagging_fraction,colsample_bytree or feature_fraction)
具体调整参数过程可以参考【6】
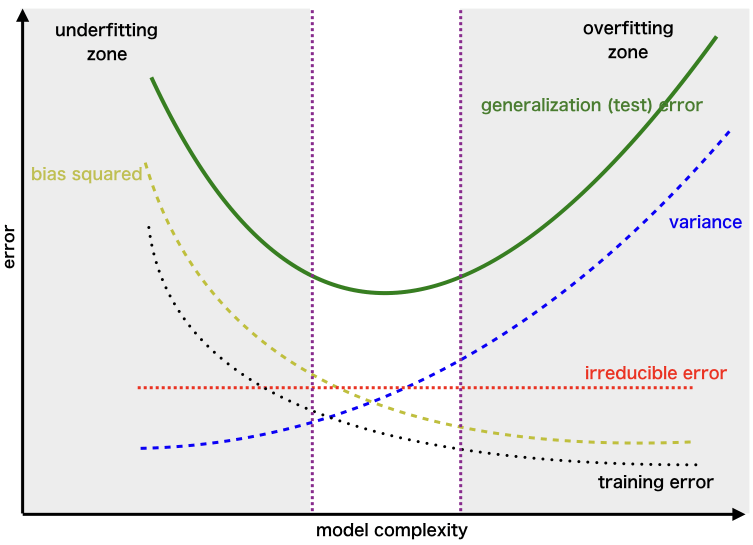
0x04 总结 4.1 经典偏差方差权衡 对于模型的效果评价分为偏差(Bias)和方差(Variance),其中偏差反映的是模型的准确程度,比如说GT是1,偏差预测的结果为(2.1,2.2,1.9),这种属于高偏差,低方差,说明模型是欠拟合,此时模型还没有学习到模型背后的假设。而当GT是(1.2,1.3),模型的预测结果为(1.2,1.3)说明模型具有低偏差但是具有高方差,说明此时模型不仅学习到了假设同时也包含了噪声,导致过拟合
modelcomplexity
在集成学习如何解决 bias- variance tradeoff
bagging and variance:
通过学习的方式,可以看出bagging方式训练了很多模型,但是并没有显著的提高模型的效果,所以有可能所有的模型的效果并不是很好,但是通过大数定律来提高集成模型的效果,也就是减少模型的variance
boosting and bias:
boosting的方式也就是在不断的学习残差或者梯度的过程,是在不断的减少模型的bias
4.2 如何学习 获取模型算法的设计过程无关,但是前期的特征工程和对比分析也非常有意思!
[1]基于LightGBM的时间序列预测
[2]LightGBM回归预测模型构建
[3What is Light GBM? Advantages & Disadvantages? Light GBM vs XGBoost?]
[4]LightGBM
[5]lightGBM调参教程
[6]非常棒的调参过程
[7]Bias and variance