CS285 动手学强化学习 Vol2 | 行为克隆
目标是明白RL中的一些定义(definition)和记号(notation),主要是从MDP的定义,然后模仿学习(Imitation learning)和$\epsilon$-greedy 学习的角度介绍了强化学习中的case
0x01 Definition of Sequential decision problem
1.1 概率论
关于概率论的记号,与研一课程《应用统计》不一样。我猜想多是具有另外的规定,这里引用从《Deep learning》(2015,Lan Goodfellow)中的说明:
随机变量(random variable)是可以随机取不同值的变量,我们通常使用无格式字体(plain typeface)中的小写字母表示随机变量本身,用手写体中的小写字母表示随机变量能够取的值。$x_1,x_2$表示随机变量x可能的取值,对于向量(vector)的变量,我们通常用x,可能的取值为$x$。所以$p($x$=x)$可以简写为$p(x)$
1.2 强化学习
与强化学习典中典的:环境(Environment)与智能体(Agent)和动作(Action)三者交互类似,CS285课程同样以这样的例子作为开端,并利用概率图的方式来分析这个过程。
- (第一层)在草原这个环境中看到了某个东西,然后我们判别出来它是老虎,这个时候我们通常做出某个动作,但是我们的动作也会影响草原环境,进而影响老虎的动作
- (第二层),假设草原环境作为Environment,某个时间点的状态为State,我们作为Agent通过看认识这个状态得到Observation(老虎的概率为0.99,猫的概率为0.01),之后我们会根据Observation来采取Policy( $\pi_\theta(a_t|o_t)$)(如果是老虎,则逃跑概率=0.9,当宠物=0.1;如果是猫,则逃跑概率=0.1,当宠物=0.9);之后我们的动作action结合现有的state会影响下一步的next-state
- (第三层)$s_t$得到$o_t$,之后根据策略得到$a_t=\Pi_\theta(a_t|o_t)$,再影响下一步$s_{t+1}=P(s_{t+1}|s_t,a_t)$;state — observation — action — next_state…
在这个过程中我们会有几个疑问:
- 智能体对环境是否是完全观测(fully observe),这直接会影响我们学习的策略,通常分为$\pi_\theta(a_t|s_t)或者\pi_\theta(o_t|s_t)$ ,经常会出错
- 由图可以看出状态转移(state transit)是具有马尔可夫性质(Markov property),但是observation不一定、action也不一定、policy也不一定
- 我们的objective还不确定
在不明白目标情况下,不如去看一种简单的方式是如何学习的

image-20221024152834540
PS:强化学习的记号通常认为是研究运筹或动态规划(Dynamic programming)的Richard Bellman和研究自动控制的Lev Pontryagin不同的发展。
0x02 Imitation Learning
在Lecture01中虽然对比了强化学习(reinforcement learning)与监督学习(supervised learning)之间的差别,但是我们依旧会发现两者之间相似的地方
给出一个state或者observation,来输出一个action
因此我们可以假设存在一个专家智能体,其策略可以看成最优策略,我们可以直接模仿这个专家在环境中交互状态动作(state,action)数据来训练一个policy,而不需要环境提供的reward,这样便是imitation learning研究的问题,不需要reward信号变可以达到一个专家策略,常用的方法分为
- Behaviour Cloning
- Inverse RL
- Generative Adversarial Imitation Learning,GAIL
2.1 Behaviour cloning
输入$(s_t,a_t)$中的state作为样本输入,action作为标签,目标为
Does it ok? — No
在数据量较小的情况下,我们只能得到少量的专家数据作为训练,因此只有在数据集的分布下预测准确。但是因为我们不断经历state- observation- action- state的循环,并不是监督学习的一次终止,因此我们的每次偏差都会累积,产生复合物差(compounding error)的问题,导致差距来越来大而失败。

img
Does it ok?yes,but more data
但是在具有很多数据的情况下是可以实现的,比如**End to End Learning for Self-Driving Cars文章中收集了足够多的数据来实现运行的稳定性
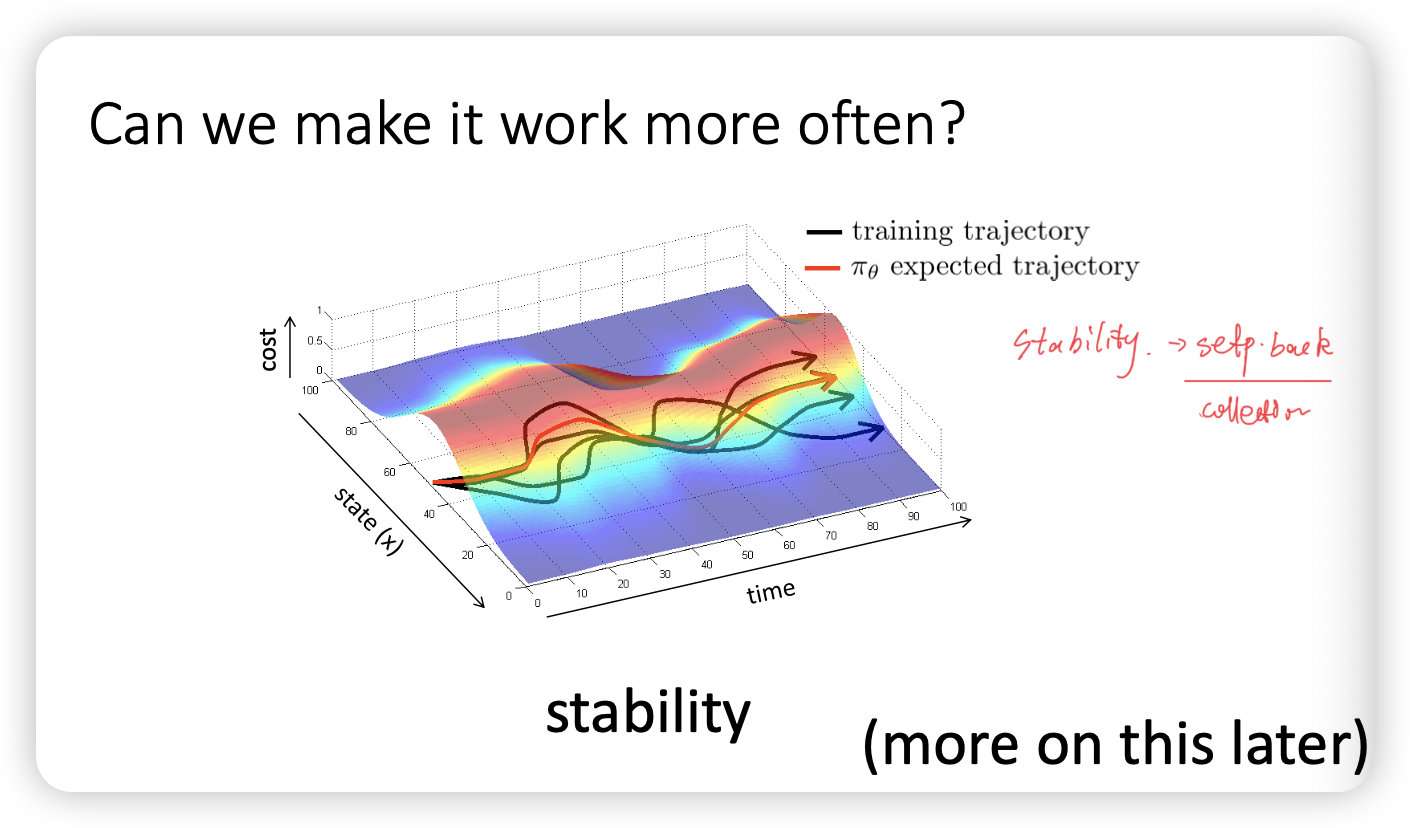
image-20221024152923468
How we make it more offen?
我们分析之间之前不同 trajectory产生偏差的原因是由于$p_{data}(o_t)!=p_{\pi_{\theta}}(o_t)$,因此我们希望用某种方式来保证,因此可以使用 DAgger(Dataset Aggregation):

image-20221024152938796
但是第一点:人工标记本身就不可靠,因为我们在相同的场景下也会出现不同的行为,同时我们的动作会和一定的记忆有关;第二点我们在复杂场景中很难准确给出新的state的action,所以本质上我们依旧需要学习机器,我们需要序列学习的概念
当然我们可以使用CNN+RNN的特点,他们依旧只是复杂的模仿学习,并没有解决分布不匹配的问题。总是我们用DAgger来解决这样的问题,依旧只是在特定场景下具有可能性。
0x03 A little bit of theory for imitation learning
可以不看,因为看不懂!
结合之前基本概念里的MRP(Markov reward process)我们可以理解reward,因此在一段轨迹中我们希望,首先我们定义cost
同时cost反面等于奖励,也就是
我们将真实的策略表示为$\pi^*_{\theta}(s)$,那么我们的奖励函数应该是
$r(s,a)=log p(a=\pi^*_{\theta}(s))$y
因此在采样错误率低于一定程度之下,我们可以得到

image-20221024152956985
改进之后我们有需要其他的方式来学习,这种主要是生成模型了~
3.1 生成对抗模型学习(generative adverbial imitation learning)
摘自动手学强化学习
(generative adversarial imitation learning,GAIL)是 2016 年由斯坦福大学研究团队提出的基于生成式对抗网络的模仿学习,它诠释了生成式对抗网络的本质其实就是模仿学习。GAIL 实质上是模仿了专家策略的占用度量即尽量使得策略在环境中的所有状态动作对的占用度量和专家策略的占用度量一致。为了达成这个目标,策略需要和环境进行交互,收集下一个状态的信息并进一步做出动作。这一点和 BC 不同,BC 完全不需要和环境交互。GAIL 算法中有一个判别器和一个策略,策略就相当于是生成式对抗网络中的生成器(generator),给定一个状态,策略会输出这个状态下应该采取的动作,而判别器(discriminator)将状态动作对作为输入,输出一个 0 到 1 之间的实数,表示判别器认为该状态动作对是来自智能体策略而非专家的概率。判别器的目标是尽量将专家数据的输出靠近 0,将模仿者策略的输出靠近 1,这样就可以将两组数据分辨开来。

image-20221024153011985
0x04 总结
Lecture02主要还是利用imitation learning介绍了
- 监督学习用于强化学习的局限性
- 强化学习的notation
下一章是及其Fancy的强化学习方法的总结