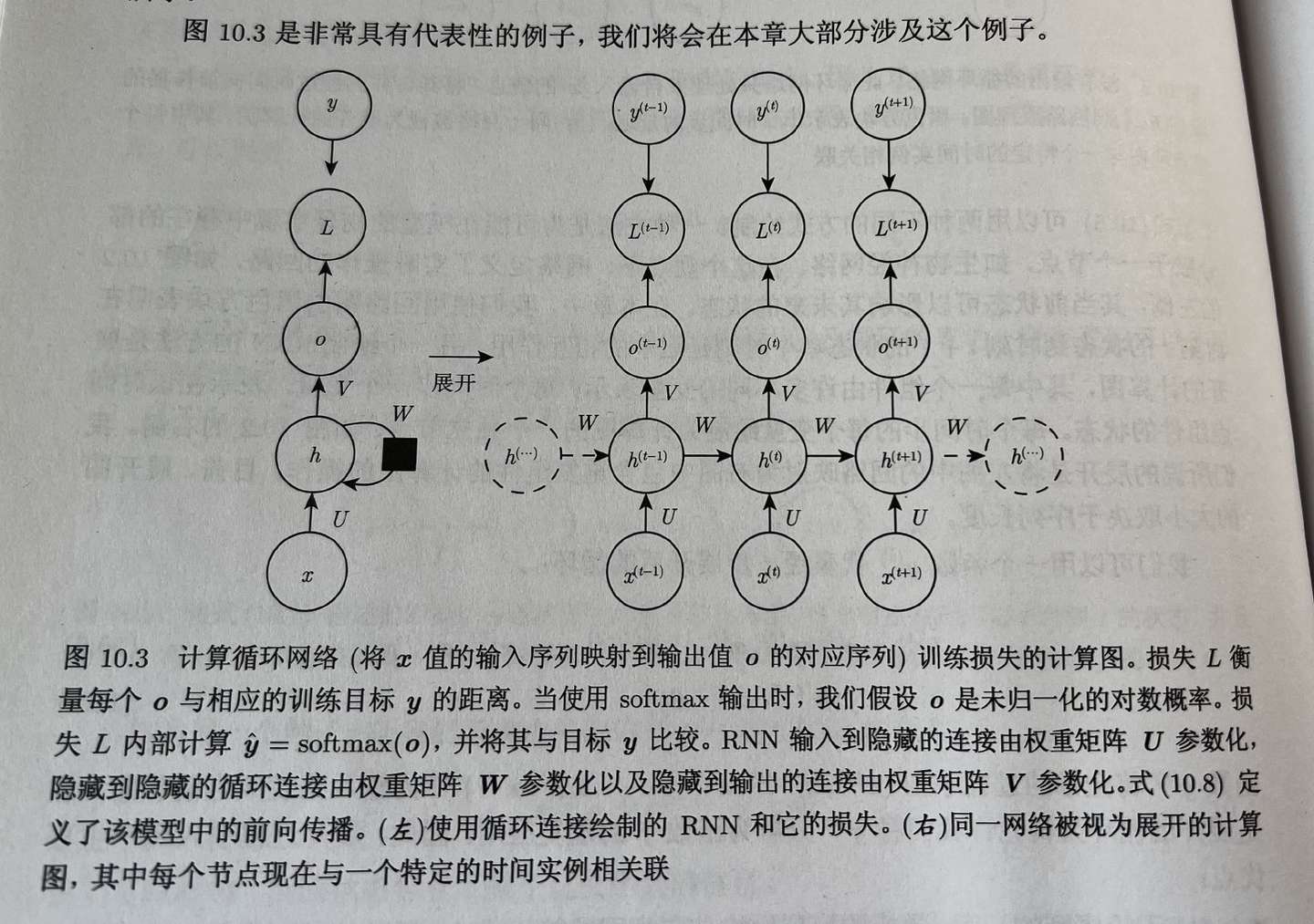
为什么RNN类似的网络在Seq中会取得好的效果?主要是解决20世纪80年代机器学习和统计模型的思想的优点:在模型的不同部分共享参数。参数共享使得模型能够拓展到不同形式的样本并进行泛化。specially:假如在seq的每一个时间点都具有一个单独的参数,但是我们不能泛化我们没有见过的类型,也不能在时间上共享不同序列长度和不同位置的统计强度。同时我们也不能理解不同顺序seq的含义(比如In 2009,I went to Nepal和I went to Nepal in 2009之间的区别)
import random import torch import math from torch import nn from torch.nn import functional as F ## 李沐中d2l服务器中存储的数据 DATA_HUB = dict() DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/' dataset='time_machine' dataset_sha256='090b5e7e70c295757f55df93cb0a180b9691891a' DATA_HUB[dataset]=(DATA_URL+'timemachine.txt',dataset_sha256)
import os import hashlib import requests import re
defdownload(name, cache_dir=os.path.join('..', 'data')): #@save """下载一个DATA_HUB中的文件 返回本地文件名""" url, sha1_hash = DATA_HUB[name] os.makedirs(cache_dir, exist_ok=True) fname = os.path.join(cache_dir, url.split('/')[-1]) if os.path.exists(fname): sha1 = hashlib.sha1() withopen(fname, 'rb') as f: whileTrue: data = f.read(1048576) ifnot data: break sha1.update(data) if sha1.hexdigest() == sha1_hash: return fname # 命中缓存 r = requests.get(url, stream=True, verify=True) withopen(fname, 'wb') as f: f.write(r.content) return fname
defread_time_machine(): #@save """将时间机器数据集加载到文本行的列表中""" withopen(download('time_machine'), 'r') as f: lines = f.readlines() return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
deftokenize(lines, token='char'): #@save """将文本行拆分为单词或字符""" if token == 'word': return [line.split(' ') for line in lines] elif token == 'char': return [list(line) for line in lines] else: print('错误:未知令牌类型:'+token)
def__getitem__(self, tokens): ifnotisinstance(tokens, (list, tuple)): returnself.token_to_idx.get(tokens, self.unk) return [self.__getitem__(token) for token in tokens]
defto_tokens(self, indices): ifnotisinstance(indices, (list, tuple)): returnself.idx_to_token[indices] return [self.idx_to_token[index] for index in indices]
defcount_corpus(tokens): #@save """统计词元的频率""" # 这里的tokens是1D列表或2D列表 iflen(tokens) == 0orisinstance(tokens[0], list): # 将词元列表展平成一个列表 tokens = [token for line in tokens for token in line] return collections.Counter(tokens)
defload_corpus_time_machine(max_tokens=-1): #@save """返回时光机器数据集的词元索引列表和词表""" lines = read_time_machine() tokens = tokenize(lines, 'char') vocab = Vocab(tokens) print(vocab.idx_to_token) # 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落, # 所以将所有文本行展平到一个列表中 corpus = [vocab[token] for line in tokens for token in line] if max_tokens > 0: corpus = corpus[:max_tokens] return corpus, vocab
num_batches = num_subseqs // batch_size for i inrange(0, batch_size * num_batches, batch_size): # 在这里,initial_indices包含子序列的随机起始索引 initial_indices_per_batch = initial_indices[i: i + batch_size] X = [data(j) for j in initial_indices_per_batch] Y = [data(j + 1) for j in initial_indices_per_batch] yield torch.tensor(X), torch.tensor(Y)
num_epochs, lr = 5000, 0.5 # loss function loss=nn.CrossEntropyLoss()
# optimer or updater defsgd(params, lr, batch_size): """Minibatch stochastic gradient descent. Defined in :numref:`sec_utils`""" with torch.no_grad(): for param in params: param -= lr * param.grad / batch_size param.grad.zero_()
ifisinstance(net,nn.Module): # what is for?? updater=torch.optim.SGD(net.parameters(),lr) else: print('net is not as nnModule') updater=lambda batch_size:sgd(net.params,lr,batch_size)
defgrad_clipping(net, theta): #@save """裁剪梯度""" ifisinstance(net, nn.Module): params = [p for p in net.parameters() if p.requires_grad] else: params = net.params norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params)) if norm > theta: for param in params: param.grad[:] *= theta / norm
for epoch inrange(num_epoches): state=None res=[] for X,Y in train_iter: if state isNoneor use_random_iter: state=net.begin_state(batch_size=X.shape[0],device=device) else: ifisinstance(net,nn.Module) andnotisinstance(state,tuple): state.detach_() else: for s in state: s.detach_()
ifisinstance(updater,torch.optim.Optimizer): # judge is handSGD updater.zero_grad() l.backward() grad_clipping(net,1) updater.step() else: # define in d2l.sgd l.backward() grad_clipping(net,1) updater(batch_size=1) res.append(l) print('困惑度{}'.format(str(res[-1])))
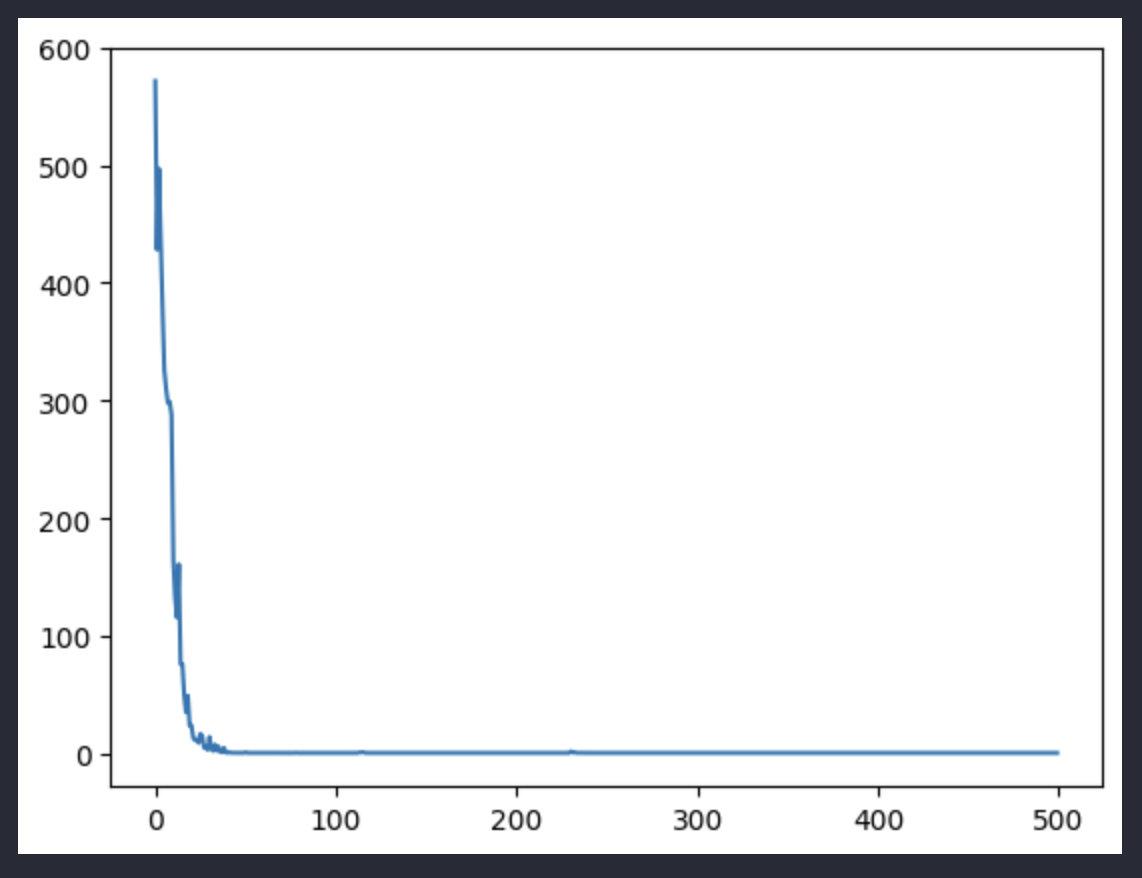
4.5 结果
肯定都能训练出来
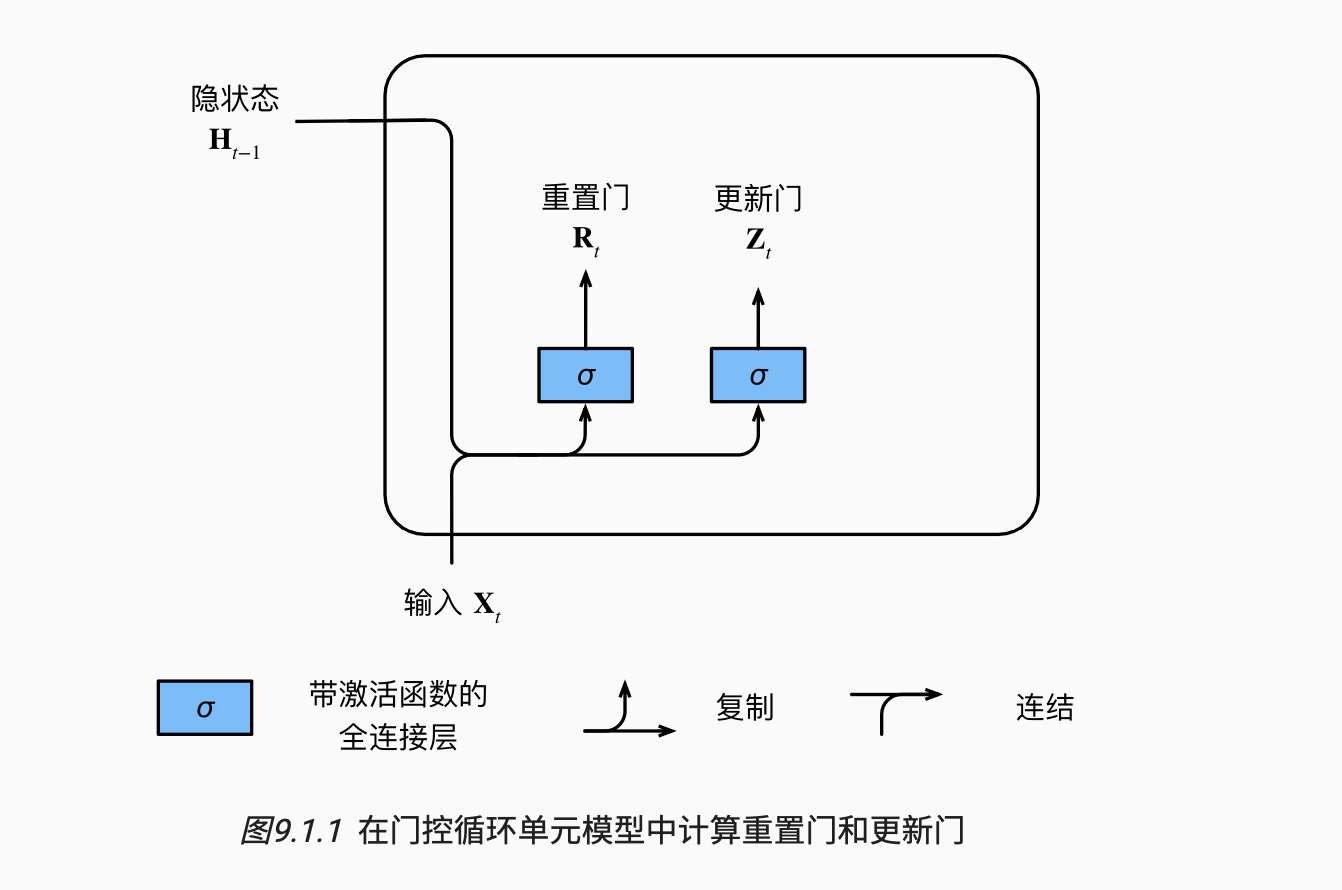
GRU结果
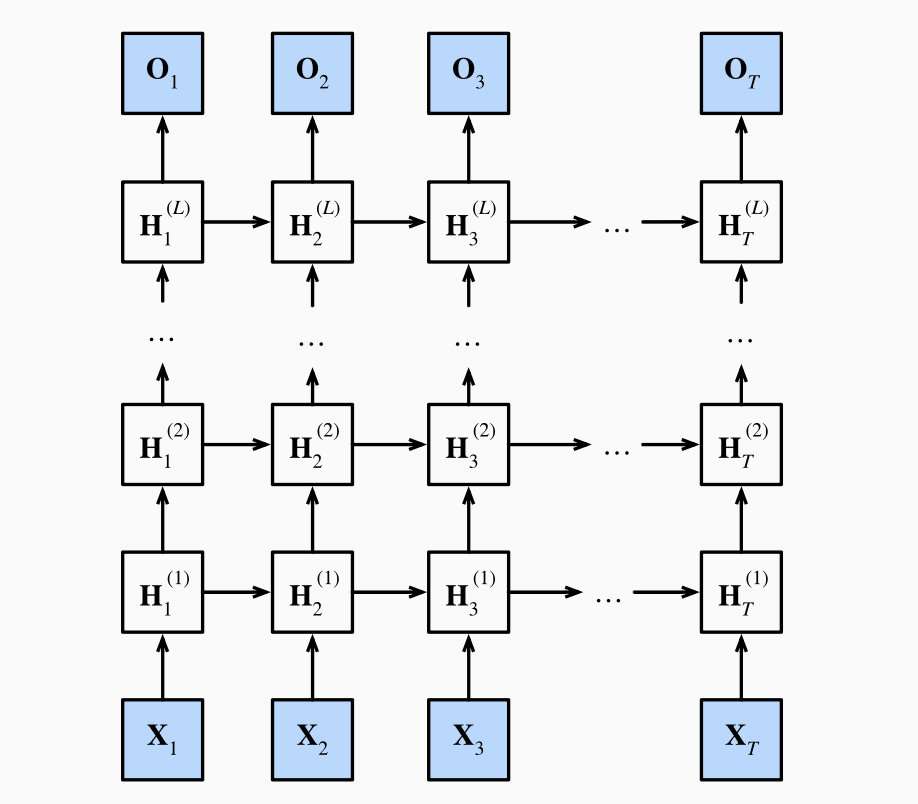
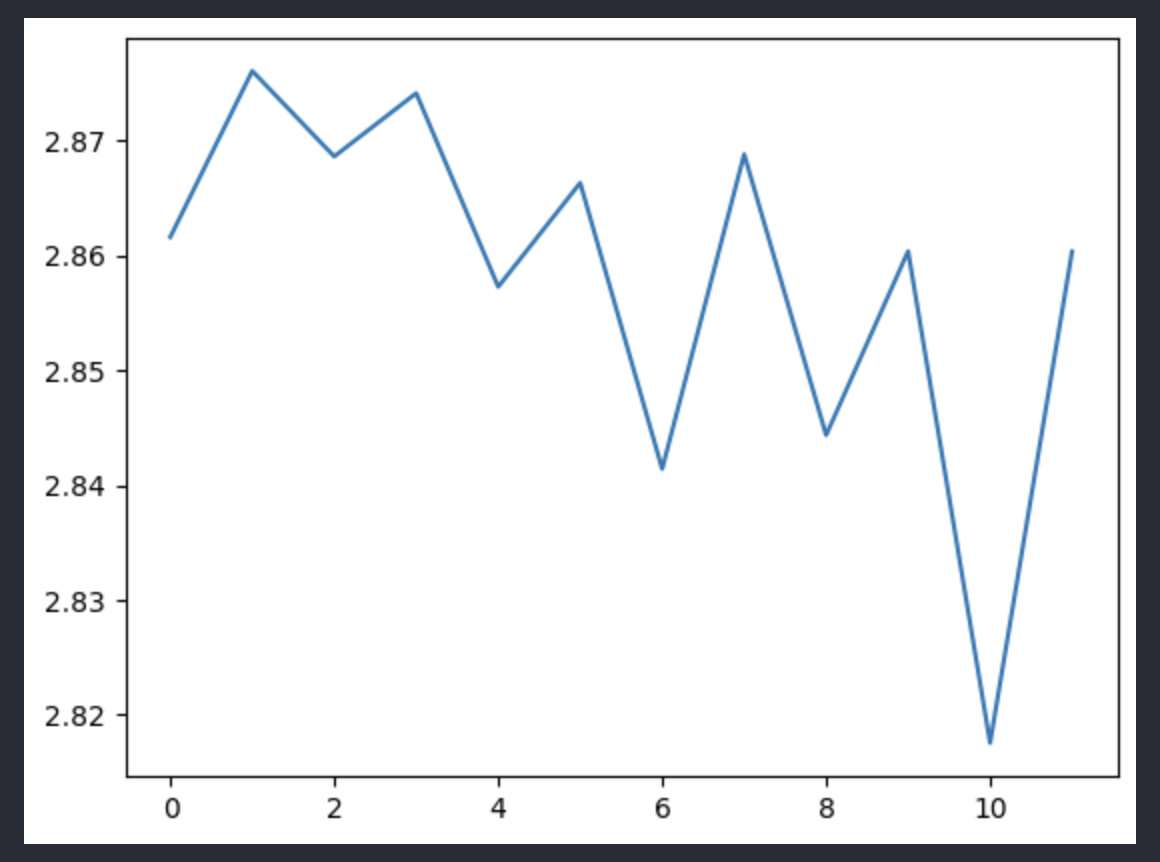
使用word的训练时间会大于char很多
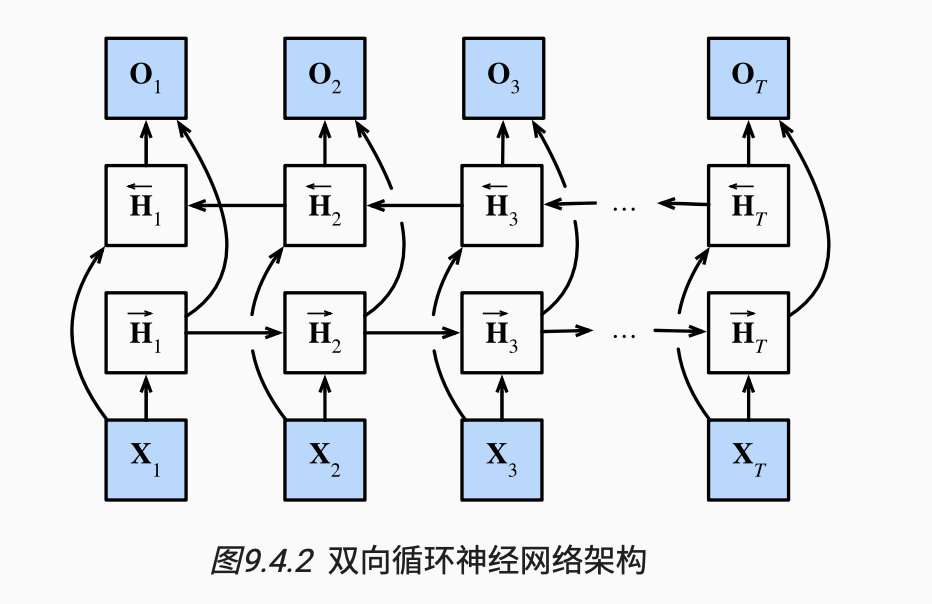
word的训练过程
给他一个time traveller,可以得到这个:
time traveller stooping to light a spill at the fire then he turned lighting his pipe to look at the psychologist s face the psychologist to show that he was not unhinged helped himself to a cigar and tried to light it uncut what is more i have a big machine nearly