动手学深度学习 Vol8 | transformer 总结和解释
这次详细介绍一下transformer框架,以及潜在的想法。在我心中这个是和Alexnet一样的文章。主要从基于RNN的encoder-decoder缺陷中引入attention,并从并行的角度完全引入attention。在第二章介绍attention的机制,在第三章介绍相关的论文细节。在第四章介绍基于torch的实现过程。参考了很多文章!
0x01 从RNN到Attention的Encoder- Decoder结构
在这里还没有介绍Attention之前,请把它看作是一种计算权重的方式!第二章会详细介绍,这里不了解attention不会本章的理解。
在时序信息处理中RNN、GRU、LSTM均体现出卓越的优势,通过隐藏状态可以捕获之前的信息,通过时间迁移(Time shift)来不断的预测下一个时间,通过时间梯度反向传播来弥补其中梯度的传播。同时在RNN系列的基础上,Encoder-Decoder架构完善了序列生成的模型框架,在DNA预测、机器翻译转录中取得非常好的效果。
那么什么是Encoder-Decoder框架呢?最基本、最原始的形式沐神在《动手学深度学习》中已经给出
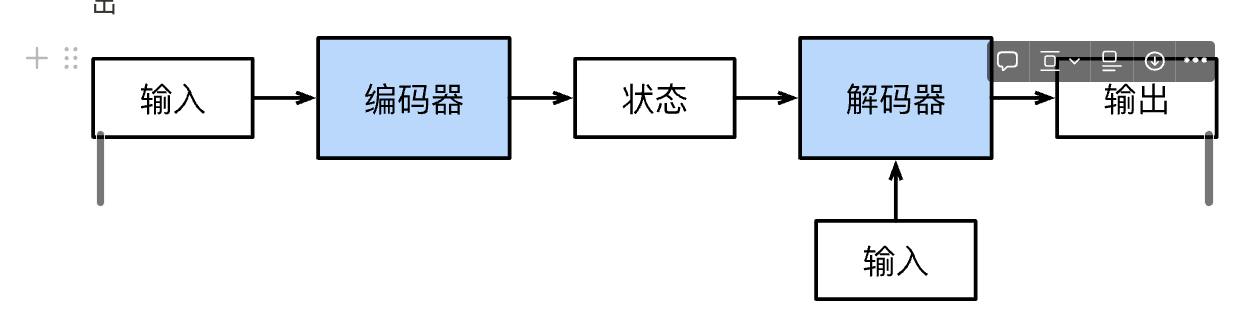
添加图片注释,不超过 140 字(可选)
但是如果直接从基本知识跳跃到《Attention is all you need》论文中会发现存在一个GAP,因为在Transformer提出之前,已经有Attention应用在编码器-解码器框架之中,我们会发现上述编码器和解码器之间的状态太过简短,如何提供一种高效的状态传递方式是值得被研究的。于是在机器翻译中Attention被引入,同是存储对应的隐藏状态
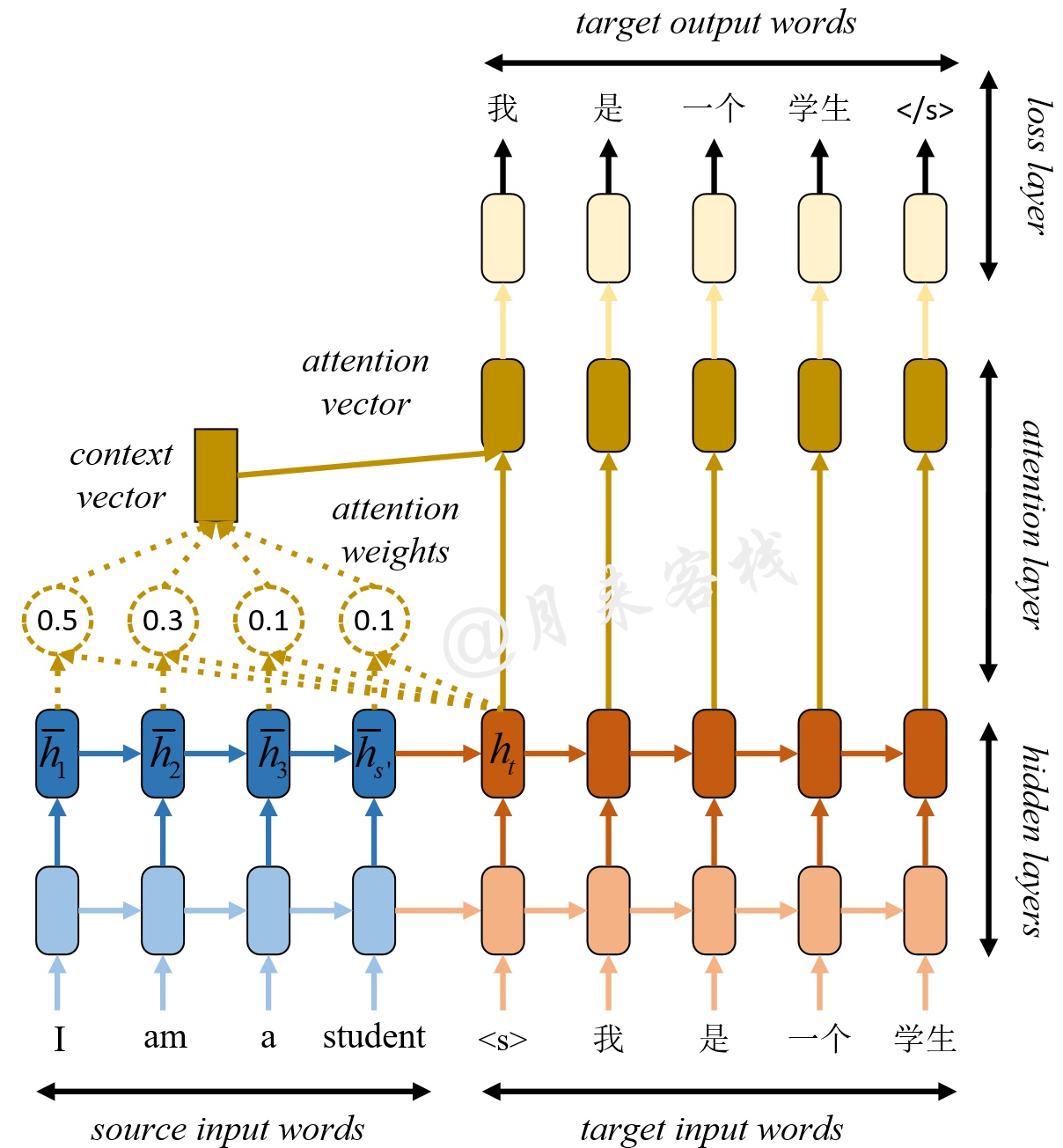
Encoder- Decoder+attention
(这里是我的想法)虽然这样引入Attention可以保证信息由Encoder传递给Decoder,但是由于RNN时间步进的限制,无法并行计算导致模型依旧训练缓慢。
那么是否有一种方式:可以得到隐藏表示向量,同时可以并行计算?第一种想法是CNN,感觉应该有相关方面的研究,第二种方法是Attention,也就是本文提出的Transformer结构。
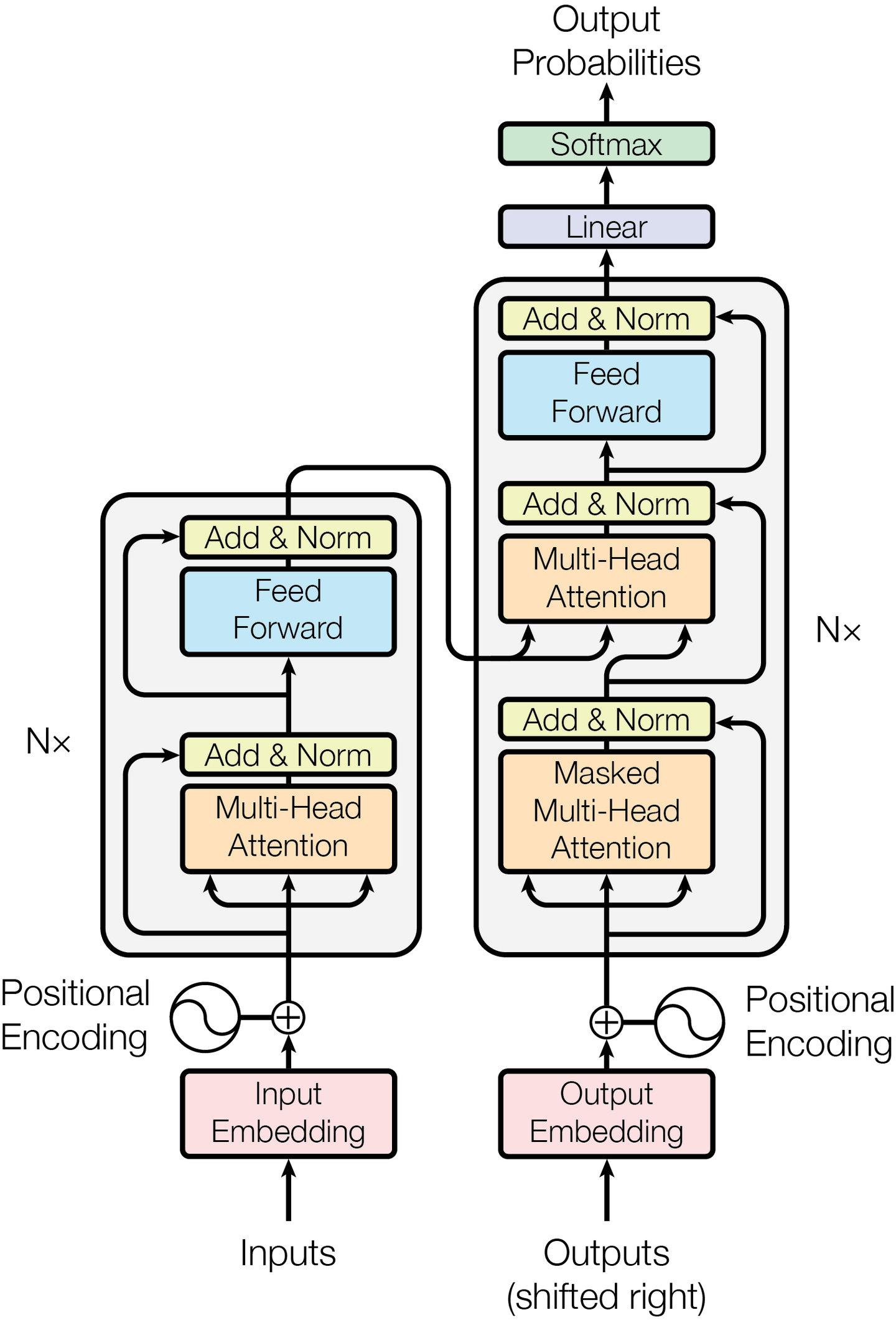
Transformer
0x02 从B站搜索到Attention维度分析
2.1 视频检索到Attention
在介绍Attention中需要包括三个部分:查询(Query)、键(Key)、值(Value)。这里以B站的视频为例子,假设这里只有seq-len=5个视频,是我们的value,每一个视频会对应不同的key,当我们给出我们的query,对于不同的query会分别与这些key进行计算得到一个权重,我们由这些权重作为相关度进行排序。(如有错误可以指出)
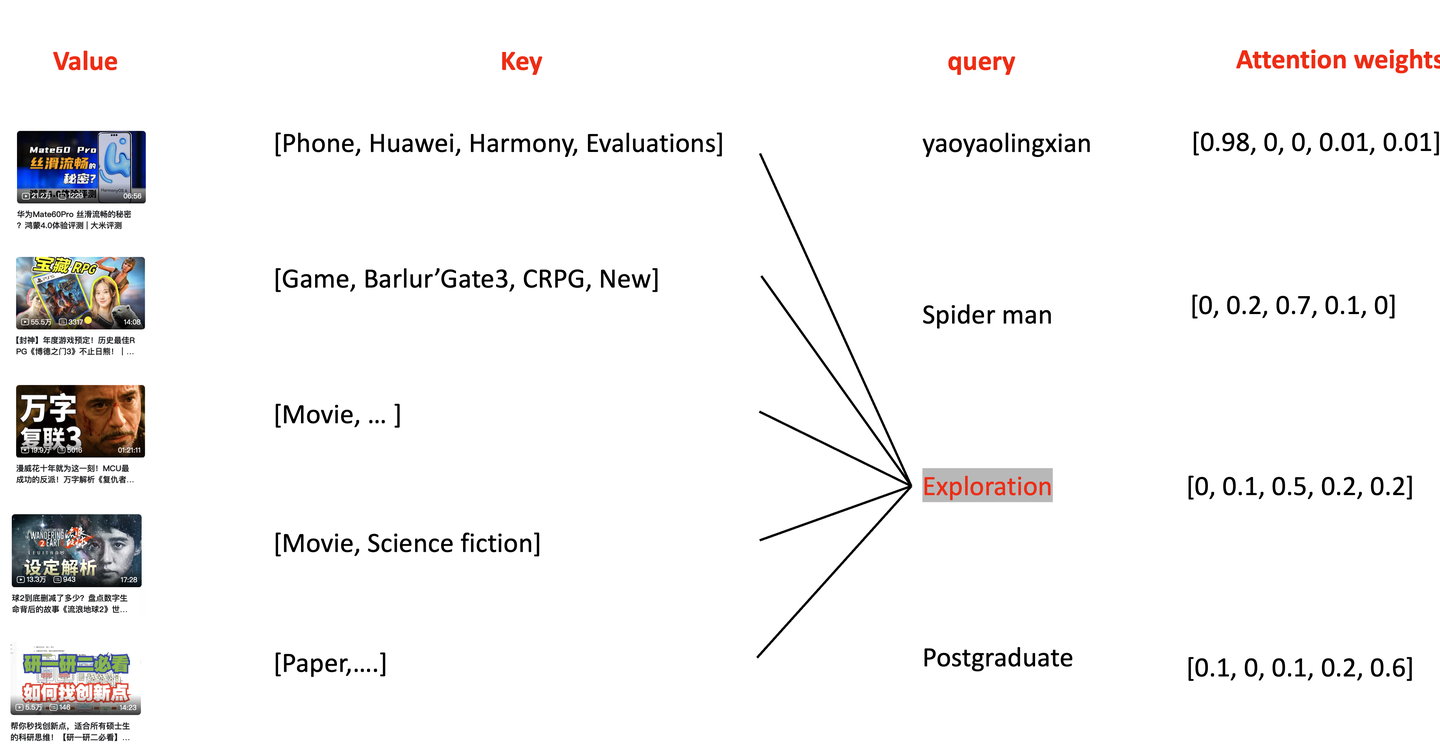
视频检索Attention
2.2 Attention维度分析
虽然这样迷迷糊糊的,最终计算的过程中都是一样的,在基于Torch的attention计算中,我们当然不能手动实现QKV的计算,因此我们简单的将原始数据输入,由内部确认权重来转换成为QKV即可。
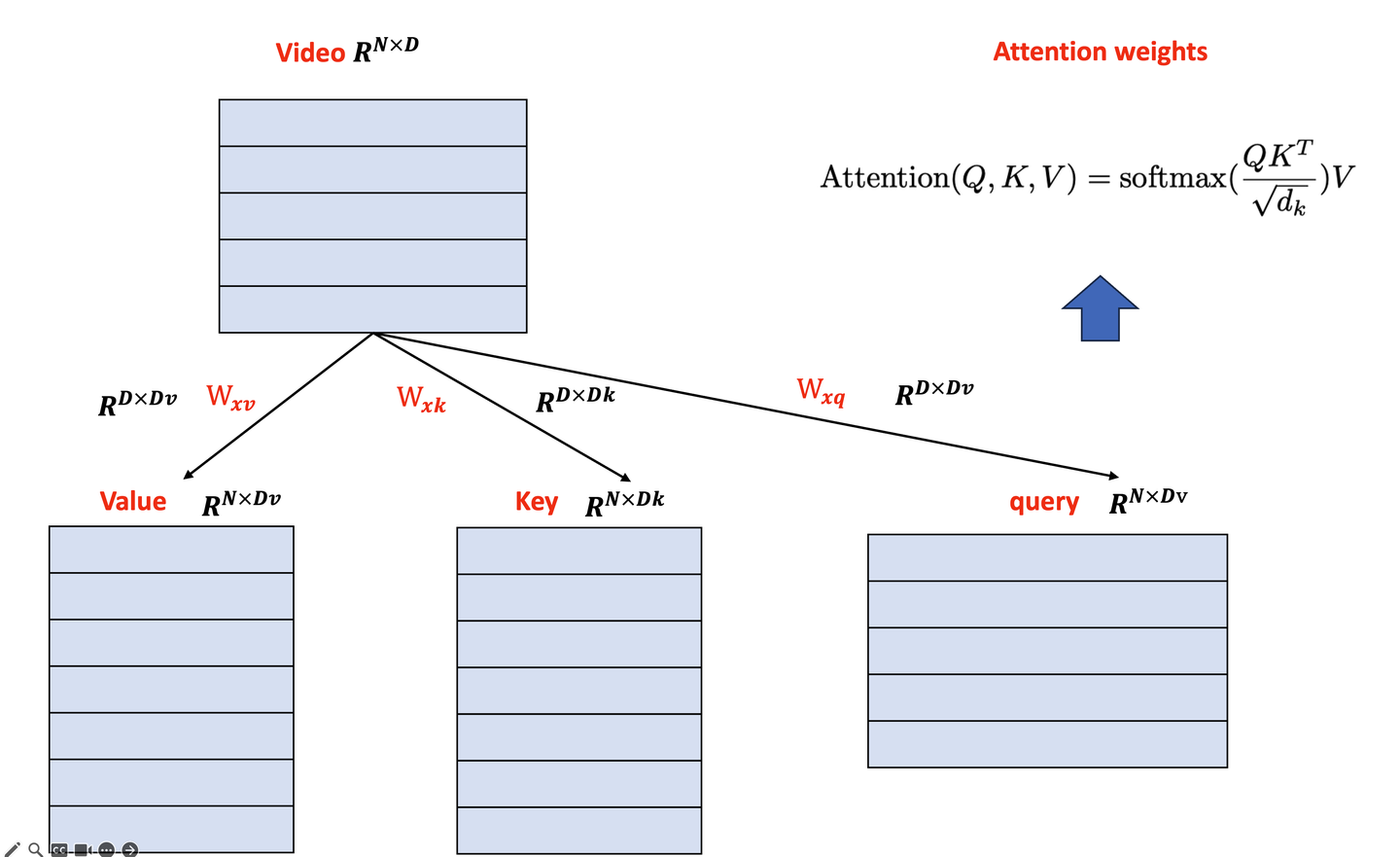
维度分析
2.3 Multi-head attention
通过上述算法我们得到一个向量,其形状一般为原始维度(N,D),这里和CNN的单通道卷积很相似,但是我们知道多通道卷积在卷积神经网络中有一定的效果,这样可以一定程度上以ensemble的思路来提高结果的准确性,因此我们可以设置Multi-head attention作为多通道输入。其具体实现是将上述的QKV拆分为按照nhead的数量来拆分,分别计算attention之后在concat
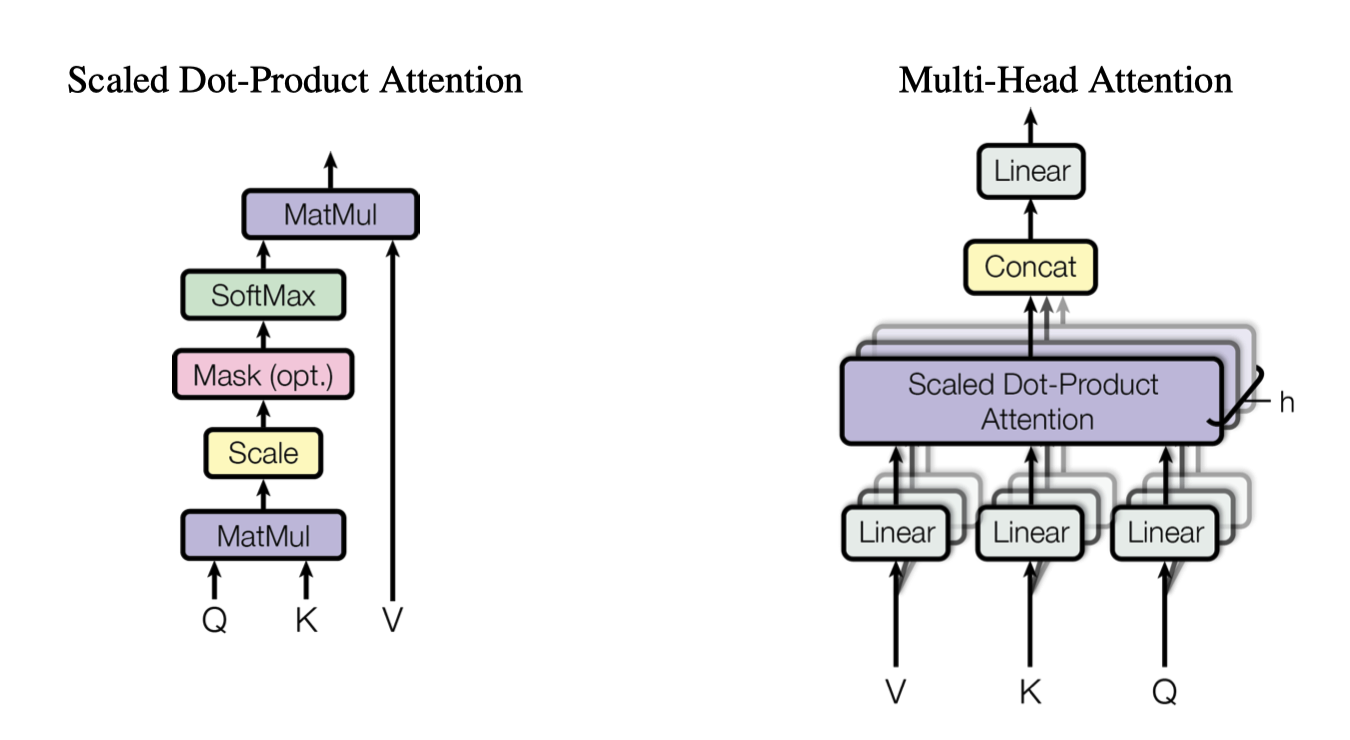
multi-head attention
2.4 Attention mask
在我们计算最后的输出的时候,在得到权重矩阵的时候要知道在decoder情况下并不能获取之后的信息,也就是在我们没有看到的数据中我们是不能计算权重的,因此我们可以设置一个可选的(Optional)来作为计算。
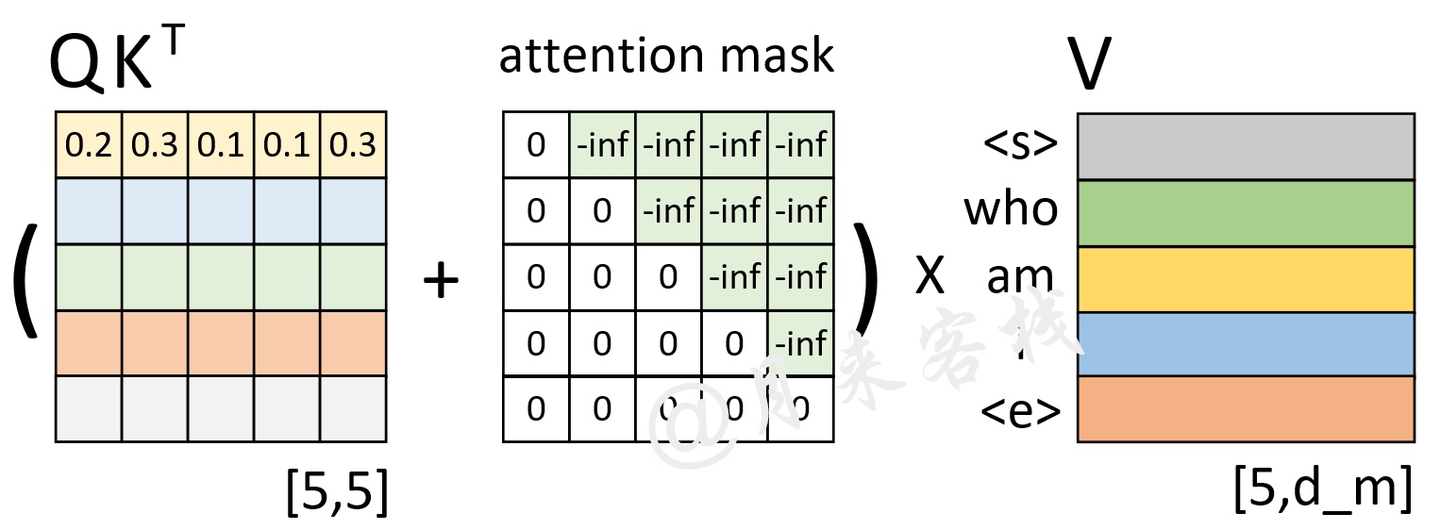
Attention Maskpng
2.5 Attention layer实现
我是手撕不了,网上有很多大神手撕的案例。但是我还是推荐观察Torch的官方代码。
0x03 魔鬼细节:Embedding,LayerNorm,Add
上述已经大体介绍Transformer的结构,但是这里依旧存在一些细节。
Embedding:将原始变量转换成为可以训练的向量,通常需要做一层语义embedding,但是除此之外,因为Transformer无法感知时序信息,通常需要Position Embedding来覆盖两者之间的顺序
LayerNorm:相比较BatchNorm可以更加容易推理,同时主要是为了模型训练的时候可以收敛。具体原因有相关论文的梯度分析
Add:参考Resnet的分析!yyds
0x04 基于Torch实现Transformer
主要是实现encoder layer、decoder layer,encoder、decoder
4.1 Embedding
1 | |
4.2 Encode layer and encoder
1 | |
4.3 Decoder layer 和Decoder
1 | |
4.4 完整的Transformer
1 | |
4.5 测试
1 | |