CS285 深度强化学习 Vol1 | 基本概念
初始强化学习最难的地方在于晦涩的专业词汇以及复杂的数学推导;同时深度强化学习并不是强化学习的终点,在这个过程中依旧需要human在其中扮演的地方。这里浅薄看蘑菇书来了解。主要作为了解强化学习的基本概念,希望从随机过程出发,来给出强化学习中智能体agent与环境 env之间的基本概念
0x01 随机过程的基础
概率论和应用统计是研究概率论中多个随机事件所构成的具有一般性规律的学科;而随机过程则是对这个过程进行描述。
1.1 马尔可夫过程 MP- Markov process
马尔可夫性质指的是一个随机过程在给定现在状态和所有过去状态的情况下,未来分布概率仅依赖于当前的状态;也就是在知道当前的状态,将来与未来是独立的
𝑃(𝑋𝑇+1=𝑥𝑡+1|𝑋0=𝑥0,𝑥1=𝑥1,…,𝑋𝑇=𝑥𝑡)=𝑃(𝑋𝑇+1=𝑥𝑡+1|𝑋𝑇=𝑥𝑡)
如果一个随机过程是离散的,可以被称为马尔可夫链(Markov chain)
在这个过程中我们看到不同状态之间的概率转换
1.2 马尔可夫奖励过程-MRP- Markov reward- process
在上述马尔可夫链的基础上,我们引入一个新的概念:
奖励- reward function:是一个期望,表示我们到达某个过程能够获得的最大的奖励,通常用horizon表示有个回合的长度,那么在奖励的基础上我们可以得到随机过程序列的回报
回报- return $G_t=r_{t+1}+\gammar_{t+2}+\gamma^2r_{t+3}+…$
这里的$\gamma$代表折扣系数;这个位置是表示这个一系列的随机过程所带来的回报,但是通常为收敛会规定 回报- return的长度来;在回报- return的基础上我们可以得到每个状态- state的价值- value;也就是回报- return的期望就是价值
𝑉(𝑆𝑇)=𝐸(𝐺𝑇|𝑆𝑇=𝑠𝑡)
这里有待讨论,感觉和高中物理中的万有引力与势能很相似
关于价值- value的求解会有很多方法
- 利用定义,遍历多种状态得到value
- 利用蒙特卡洛MC随机采样的方法
- 利用Bellman equation得到解析解
- 其他的方法,比如TD learning等
1.25关于MRP贝尔曼方程求解
太菜了,所以用手写,这样我们看出MRP重点是在知道转移概率P和各状态奖励reward以及折扣因子$\gamma$的基础上,求解出状态的价值(用不同的方法)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
1.3 马尔可夫决策过程-MDP-Markov- decision- process
MRP在MP中增加来 “奖励reward、回报return和价值value”,MDP则是继续在MRP的基础中增加动作项目action
这里的$\pi$称为是策略,在这个基础上,下一个状态应该取决于当前的状态和动作
同样 奖励reward 的定义也会更加复杂
2022-09-30 这部分后面就不太懂啦~~未完待续
1.4 举个例子
计算状态
比如状态空间包括{wechat;class1;class2;class3;sleep;pass;pub}
之间的状态概率为

添加图片注释,不超过 140 字(可选)
不同状态的reward是

添加图片注释,不超过 140 字(可选)
利用贝尔曼方程就可以得到最终的value结果
1.5 MDP的核心问题
虽然2022-09-30还没有搞懂MDP的数学过程,但是可以看出起核心的问题包括
【预测】与【控制】
预测就是给出 state、action、P、R与policy来得到每个状态的value
控制就是给出state、action、P、R来得到value与policy
在求解中常分为 策略迭代policy- iteration与价值迭代 value- iteration
细节后面在了解
0x02 强化学习概述
最经典就是这样的图,强化学习的过程可以看作是实际化的MDP过程;我们可以知道我们将问题分为 智能体agent与环境env两部分;状态state与奖励reward由env给出;agent会根据状态与奖励来实现不同的动作action(动作序列也就是需要学习的策略policy),再得到下一个状态以及当前状态得到的奖励
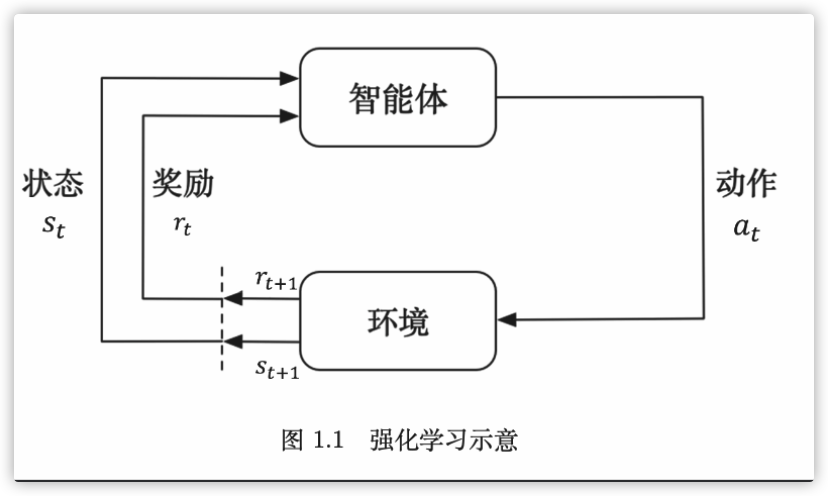
添加图片注释,不超过 140 字(可选)
0x03 强化学习与监督学习
3.1 监督学习
- 我们首先假设我们有大量被标注的数据,假设之间满足同分布,之间是没有关联的。在这个基础上我们训练我们的模型(比如一个分类器),我们可能通过将标签信息传递给神经网络,当神经网络做出错误的预测的时候我们会给他一个错误的反馈,我们利用这个错误写出一个 损失函数 loss- function,通过 反向传播 back propagate来训练
- 假设1:输出的数据应该是没有关联的
- 假设2:我们需要告诉学习正确的标签是什么,这样它可以通过正确的标签来修正自己的预测
3.2 强化学习
- 在强化学习中,监督学习的上述的两个假设都不满足
- 每个frame之间具有非常强的连续性,同时没有iid
- 强化学习中得到的训练数据是一个玩游戏的序列,我们将这个序列放进网络、希望网络输出一些动作,在这个问题中我们并没有标签来说明现在这个动作是正确的还是i错误的,必须等到游戏结束才能知道,因此这里我们面临 [[延迟奖励delayed- reward]] 的问题
3.3 区别总结
- 第一点,强化学习输入的样本是序列数据,不是iid
- 第二点,学习器并没有告诉我们每一步正确的动作应该是什么,学习器需要自己去发现那细微动作可以带来最多的奖励
- 第三点,智能体获得自己能力的过程就是 [[不断试错探索trial-and-error- exploration]]的过程, 探索exploration 和 利用exploitation
- 第四点,在强化学习过程中并没有非常强的 监督者supervisor ,只有 [[奖励信号reward- signal]],并且具有 [[延迟奖励delayed- reward]] 的情况
0x04 序列决策
4.1 奖励 reward的定义
是环境给的一种 [[标量反馈信号-scalar-feedback-signal]],这种信号显示智能体在某一步才去某个策略的表现如何
4.2 序列过程描述
强化学习中一个重要的课题就是近期奖励和远期奖励的权衡,也就是如何让智能体可以获得更多的远期奖励
在与环境的交互过程中, [[智能体agent]] 会获得很多 [[观测observation]] ,针对每个 [[观测observation]] , [[智能体agent]]会采取一个 [[动作action]],然后获得 [[奖励reward]],所以这样的序列是
[[智能体agent]]在采取当前动作的时候会依赖之前得到的历史,因此可以将整个学习的[[状态state]]看作是这个历史的函数
4.3 观测 observation 与 状态state区别

添加图片注释,不超过 140 字(可选)
4.4 动作action
分为离散与连续
4.5 智能体分类
第一种分类:
- 基于policy划分;随机与确定
- 基于value- function;value或Q函数
- 模型model;模型决定下一步的状态,状态取决于当前的状态以及当前采取的动作,由 [[状态转移概率]]和 [[奖励函数]]组成

添加图片注释,不超过 140 字(可选)
第二种分类:
- 基于价值的智能体
- 基于策略的智能体
- 演员评论员智能体

添加图片注释,不超过 140 字(可选)