动手学深度学习 Vol4 | Attention机制
本来就以Attention为基础的Transformer结构很感兴趣,想直接从CNN跳到Attention来学习,但是通过了解一些基本的背景发现并不现实,transformer的提出本来就是在机器翻译的基础上,所以先天的在一些问题场景的解释中并不是以回归数据、或者说二维图像数据,而是基于序列(seq)类型的数据进行解释的,所以需要在了解认清楚seq2seq学习之后才能对attention有一些理解。这次只是对attention作为简单的了解,并对深度学习中一些做出review,来修正自己之前错误的看法以及重建新的世界观。
0x01 什么是Attention(文字版)
1.1 从生物学玄学的说起注意力 attention
(很有意思的一段) 注意力是稀缺的,而环境中干扰注意力的信息并不少。比如我们的视觉神经系统大约收到10e8位的信息,远远超过了大脑能够完全处理的水平,但是幸运的是我们的祖先已经通过经验认识到“并非感官的所有输入都是一样的”,在整个人类历史中,这种将注意力引向感兴趣的一部分信息的能力使得我们的大脑能够更加明智地分配资源来生存、成长和社交,例如发现天敌、找寻食物或者伴侣
生物学中常见的利用双组件(tow- component)来解释注意力,将注意力划分为两类:
- 非自发:单纯的根据观察到的”数据“来确定你所注意的的东西,比如桌子上有试卷、可乐、游戏机、一个钥匙和一个活动的公鸡;你可能最先关注的鸡
- 自发性:在自我意识的控制下来选择关注合适的元素,比如上述如果你是为了寻找一个钥匙而来,那么你就会将注意力专注到对应的元素中。
1.2 害死人的Q(query)、K(key)、V(value)
这里的起源利用另外一种Notation来表述,定义如下:
query:自主性提示成为query
key:自主性提示
attention pooling:注意力汇聚,将 选择(output)引导感官输入
感官输入称为value,每一个value都与一个key匹配
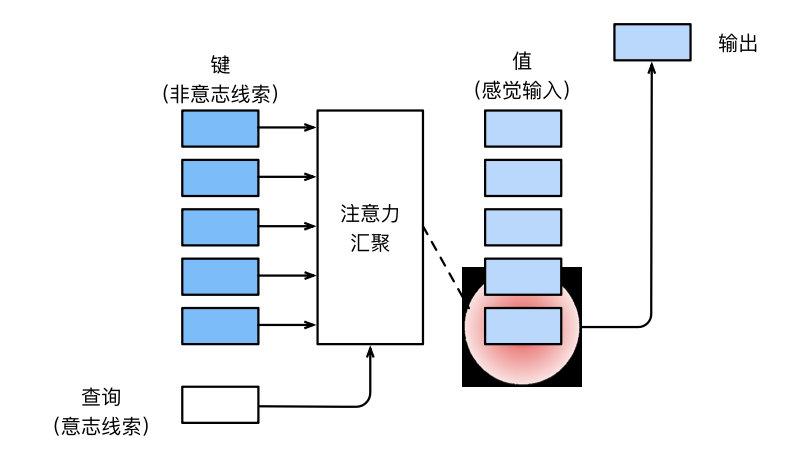
image-20221013203214511
1.4 利用找书小故事来解释QKV模型(个人猜想!)
我们将图书馆里面所有的书称为Key,每个书可能会对应不同的value(看或者不看);当我们有自己的query(想看交通方面的书),就会将query对不同的key进行attention pooling,这样output就是与交通相关的书才会看,与交通不相关的书不看。

image-20221013203802267
1.5 从机器学习里的 来看(个人猜想!)
其中的 相当于Key, 相当于Value
当我们对一个新的$x$预测的时候相当于是对这个发出query,这个时候我们会怎么样?
- 首先根据$x$与$X={x^{(i)}}i=1…n$进行attention score的计算,然后再归一化(比如softmax)
- 之后再利用归一化的结果作为 权重 来拟合得到output
这里与线性回归的区别在于权重的确定和使用上,线性回归的权重是严格推导并使用在X的不同特征上,而attention的权重是通过学习并使用在X(key)对应的y(value)
同时这里的attention value的权重可以是通过学习,也可以是通过人为定义来得到的,因为我们采用的vector形式的学习,因此我们可以使用kernel function或者线性空间一些距离度量来作为计算方式,在后续进化版的升级中,我们可能会会有其他score的度量,比如书与书之间是好度量的,但是说的话和书之间如何度量?
0x02 可视化Attention
接着上述的1.5我们可以看出《D2L》书中介绍Nadaraya- Watson核回归,只不过其中的attention score 的计算方式是用核机器;幸运的是我们在SVM里面已经初步了解过,它只是一种将低纬度的向量距离投射到高纬度,比如我们可以采用Gaussian Kernel
这样取评价之后就可以得到我们对于新的query的x的预测为
这里取的就是按照一种高斯距离,离的越近越好,如果按照这个方式得到的attention score可以看出近大远小的特点。
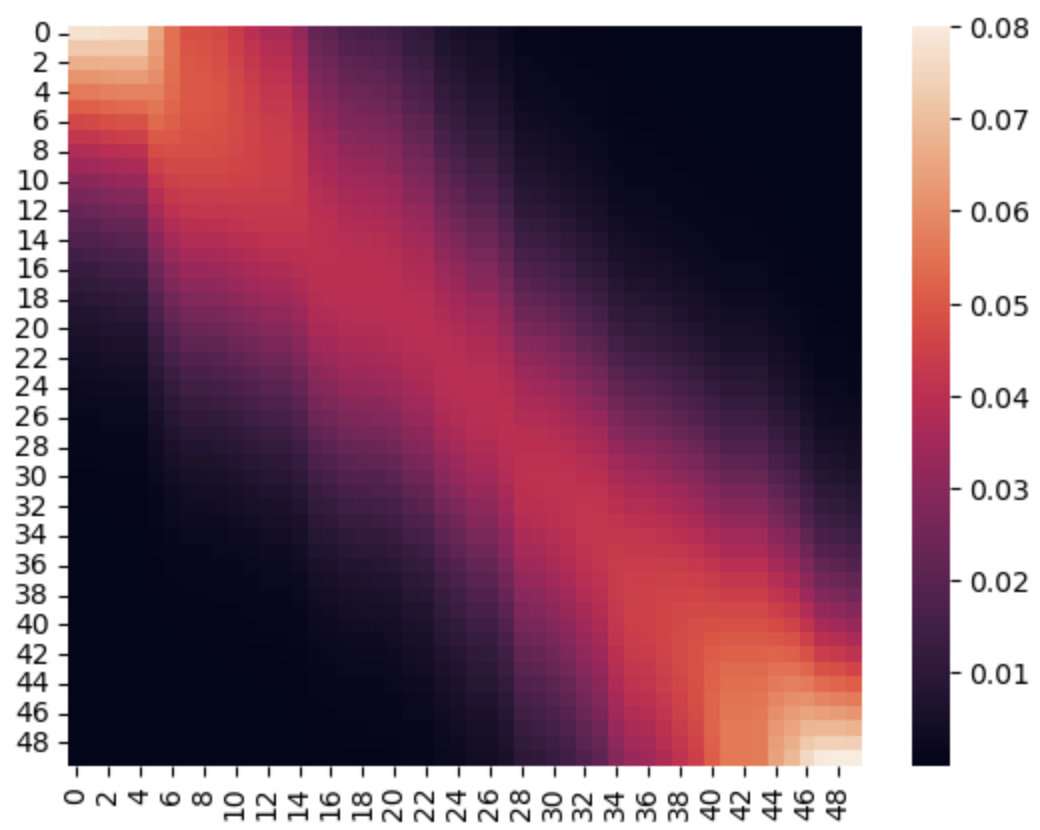
image-20221013205856315
但是另外一种我们希望可以对于不同query具有不同的高斯函数的宽度,也就是我们希望方差不一样
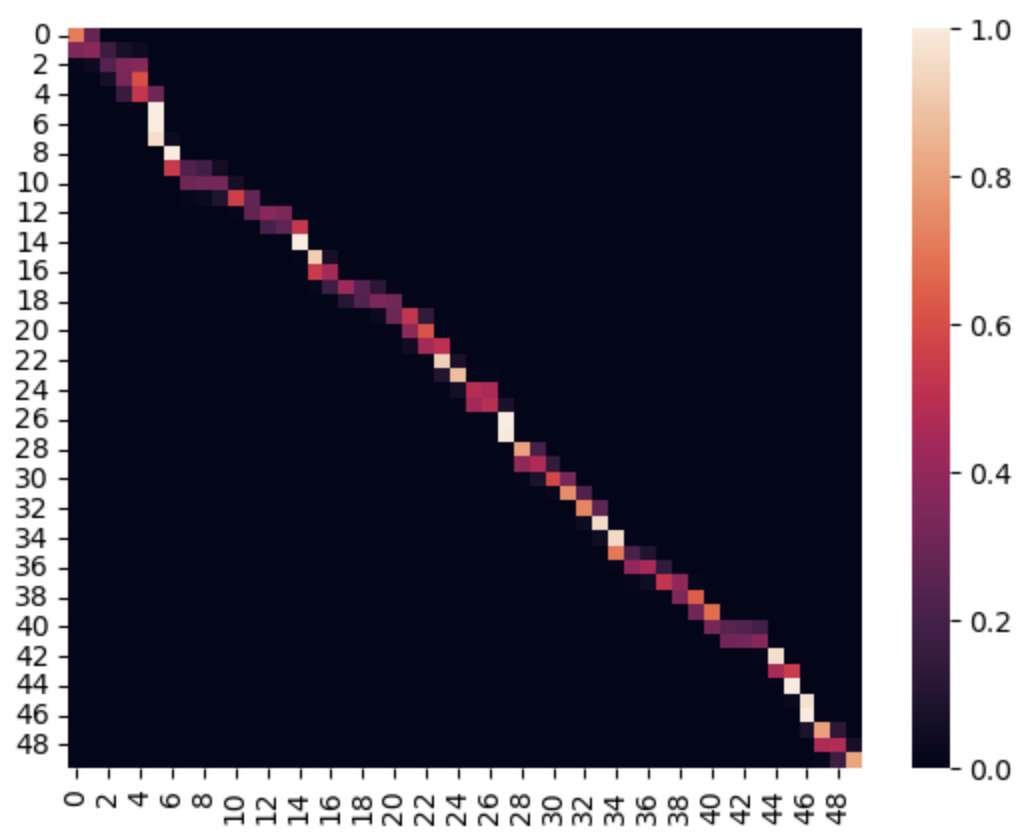
image-20221013210023487
这样对于不同的value就会有不同的权重(注意这里的权重值得不是w),指的是利用w计算出来的attention score
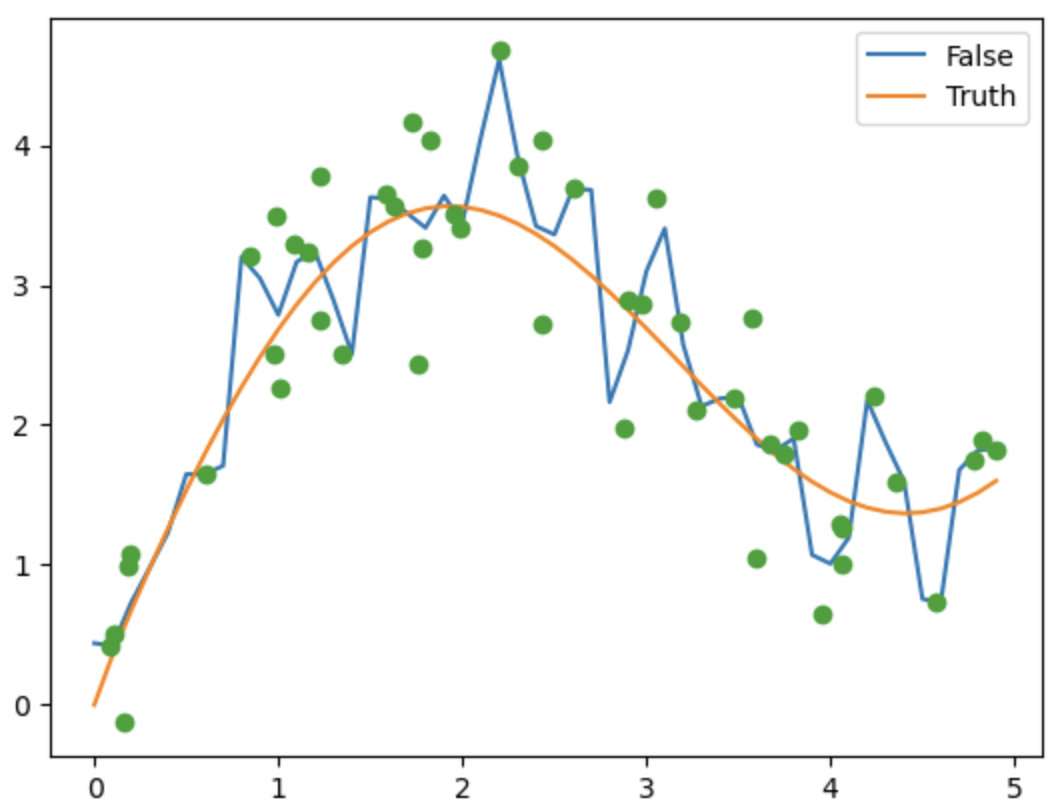
image-20221013210112922
0x03 对于attention的初识
所以attention是啥,如果利用QKV的角度来看比较复杂,如果从简单的回归问题角度来看它只是另外一种计算权重方式的函数。
但是!attention的作用不仅局限于回归问题,它从seq问题中而来,解决的就是CNN或者RNN对于距离的敏感性。
就像CNN的感受野,对于单层感受野可能是固定好的(与kernel size、padding、step有关),但是多层累积中感受野是可以逐渐扩大的。但是CNN适用于图像的可能解释是一,图像的维度是固定size的(像素无论多大都是有限的)
而RNN的感受野,借鉴被人的说法是取决于词元模型和hidden layer,但是由于hidden layer也是具有顺序的特征,它的感受野也不会传递的太远。
attention利用attention socre对不同的key进行筛选,来得到一个足够远但是量不大的感受野。选择重要的数据。

image-20221013210849152
同时在Attention中关于attention score的计算过程中,由于没有接触过seq2seq模型,在后面的计算中可能需要了解之后才能有更近一步的认识。目前的理解是利用一种可学习的方式来得到合理的attention score的计算方式。
flag:
看懂RNN、GRU、LSTM
明白seq2seq框架,encoder- decoder的框架
0x04 Discussion
4.1 一致记号的重要性
还是很喜欢CS229的讲义中Notation一致性的思考,这样前后的公式推导会很清晰,在解释问题中会有一致性
D2L中沐神讲的真的很好,但是在写作中似乎还是缺少这种基本的素养。这样的素养对于大佬是锦上添花,但是对于初学者是保证不出错的围栏。
4.2 模拟(print)的重要性
对于不同的抽象问题,利用具体的东西打印出来一步一步就好了。尤其是向量的每一步的size
4.3 ML&DL的一些思考
可能是沿着D2L书的缘故,对深度学习的认识过程是从MLP到CNN/GCN到RNN到Transformer,可能还有其他的,这样网络结果一样但又似乎不太一样,主要对特征提取方式上。
下面这张图可能内容不对或者不全,但是分类的思路从学习的角度还是有益的

image-20221013212732442
PS:
不幸运的网站的主题崩掉了